 2021, Vol. 41
2021, Vol. 41文章信息
- 李超凡, 范春雨, 张春雨, 赵秀海
- LI Chaofan, FAN Chunyu, ZHANG Chunyu, ZHAO Xiuhai
- 吉林蛟河阔叶红松林物种多度分布模型研究
- Species abundance distribution models of broad-leaved Korean pine forest in Jiaohe, Jilin
- 生态学报. 2021, 41(23): 9502-9510
- Acta Ecologica Sinica. 2021, 41(23): 9502-9510
- http://dx.doi.org/10.5846/stxb202010302785
-
文章历史
- 收稿日期: 2020-10-30
- 网络出版日期: 2021-07-23

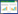




多度指物种的个体数或种群密度, 是度量物种普遍度和稀有度, 或者优势度和均匀度的指标[1]。物种多度与生物多样性一直都是宏观生态学研究的核心。物种多度研究从20世纪30年代就己开始, 它不仅是确定物种保护等级的基础, 在生物多样性研究中也具有极其重要的意义。测定物种的多度是现代群落生态学最基本的工作, 不同的群落具有不同的多度组成, 其群落中各物种的多度组成比例关系即为该群落的多度格局[2]。物种多度研究主要在两个层次上进行, 在群落水平上通过考察物种从常见到稀有的多度关系来揭示群落的组织结构; 在物种水平上通过分析物种的区域分布来阐明其形成机制[1]。
物种多度分布的拟合研究已经日趋成熟。谢晋阳等对意大利威尼托大区刺叶栎林多度格局进行了研究, 结果表明在几何分布、断棍分布、对数序列分布和对数正态分布等常用模型中, 几何分布拟合效果最好, 对数正态分布也适用[3]。马克平等对北京东灵山地区9个森林群落类型进行研究, 发现其中8个群落的种-多度格局服从对数序列分布, 7个群落服从负二项分布[4]。朱强等基于七姊妹山自然保护区内6hm2监测样地多度数据, 采用6种模型对各功能群不同取样尺度物种等级-多度曲线进行拟合并检验其拟合效果, 发现随着尺度逐渐扩大, 中性过程较生态位过程对物种-多度格局的解释力度更大, 落叶树种物种多度格局的形成机制较常绿树种更接近于样地所有树种物种-多度格局的形成机制[5]。张金屯发现美国纽约州阔叶林的种-多度格局可用分割线段模型进行拟合[6]。钟雄等应用生态位优先模型, 对数级数模型和对数正态分布模型, 对巴东县野三关红椿天然群落乔灌草层的多度分布进行拟合, 发现3种模型均不能描述草本层物种多度分布, 但均可以较好地拟合灌木层和乔木层的物种多度格局[7]。殷作云通过种-多度对数正态分布模型得到个体多度分布模型, 并进一步从中推导出估计总体中总个体数的公式[8]。石培礼等发现截尾对数正态分布和对数级数分布能较好地拟合交错带附近群落的种-多度分布, 而截尾对数正态分布模型更适合交错带群落[9]。坤杜孜·萨塔尔等以艾比湖流域荒漠生态系统为研究对象, 选取1hm2荒漠植物群落样地, 基于6个取样尺度利用不同的生态学模型拟合植物群落的分布格局, 发现虽然基于不同尺度下荒漠生态系统在群落组成上有明显的变化, 但影响物种多度分布格局的生态学过程基本一致, 可初步推断中性理论对荒漠植物群落物种多样性维持过程中显得更为重要[10]。余世孝等发现海南霸王岭不同热带森林类型的种-个体关系符合对数正态分布[11]。李旭光等对绵阳官司河流域防护林物种多样性的研究[12]、王文颖等对青海高山嵩草草甸植物群落的研究[13], 也得到了类似的结论。吴承侦等对福建万木林保护区观光木群落研究表明, 乔木层物种的相对多度分布可用对数级数分布、对数正态分布、Weibull分布、几何级数分布和分割线段模型来拟合; 而灌木层物种相对多度分布可用对数级数分布、对数正态分布和Weibull分布进行拟合[14]。张雪皎等通过野外调查获取了华北及周边地区1045个样方的栎属树木多度, 利用广义线性模型、广义加性模型和随机森林模型模拟5个树种多度的地理分布, 发现随机森林模型对5个栎属树种的多度的拟合结果要优于广义线性模型和广义加性模型[15]。
上述研究主要围绕对数级数、对数正态、断棍、几何序列等几种常规模型开展讨论。随机分布和负二项分布等理论模型对温带阔叶红松林物种多度拟合效果仍不清楚。本文采用随机分布模型和负二项分布模型, 在不同研究尺度上分析吉林蛟河阔叶红松林的物种多度分布。一方面探究阔叶红松林物种多度构成及其聚集或随机性; 另一方面通过对比拟合模型的预测与观测多度来检验两个模型的科学性与实用性。
1 研究区概况和研究方法 1.1 研究区概况研究区位于吉林省林业实验区国有林保护中心(127°35′—127°51′E、43°51′— 44°05′N), 属于长白山系张广才岭山脉。该区域属于温带大陆性季风气候, 年均温3.8 ℃, 最热月是7月, 平均气温是21.7 ℃, 最冷月是1月, 平均气温是-18.6 ℃, 年均降水量700 —800 mm, 多集中在夏季。该区域土壤为暗棕色森林土, 土层厚度为20—90 cm。样地海拔在459—517 m。该研究区植被类型属于长白山植物区系, 以受人为干扰较小的阔叶红松林为主, 主要的乔木树种有红松(Pinus koraiensis)、白牛槭(Acer mandshuricum)、胡桃楸(Juglans mandshurica)、春榆(Ulmusdavidiana var. japonica)、水曲柳(Fraxinus mandshurica)等。主要的灌木有毛榛子(Corylus mandshurica)、簇毛槭(Acer barbinerve)、东北山梅花(Philadelphus schrenkii)等。
1.2 样地设置与概况2010年7月, 在研究区内选择远离居住区, 受人为干扰极少的老龄阔叶红松林, 建立30hm2(500m×600m)固定监测样地(图 1)。调查过程中采用全站仪将整个样地划分成750个20m×20m的连续样方, 用水泥桩在20m处结点位置进行标记。

|
| 图 1 吉林蛟河30hm2动态监测样地的地形图 Fig. 1 Topographic map of 30 hm2 dynamic monitoring plot in Jiaohe, Jilin |
对样地内所有胸径(DBH)≥1cm的木本植物进行初测, 记录物种名、胸径、树高、冠幅、枝下高及相对位置, 同时挂牌定位。在阔叶红松林样地中, 共监测到木本植物50种, 物种基本概况如表 1所示。
| 物种缩写 Species abbreviations |
物种名 Species |
重要值/% Important value |
多度 Abundance |
断面积和/m2 Basal area |
最大胸径/cm Max. DBH |
| ACMO | 色木槭Acer mono | 28.53 | 4253 | 12.1704 | 88.9 |
| ULLA | 裂叶榆Ulmus laciniata | 27.47 | 2769 | 13.4628 | 88 |
| CACO | 千金榆Carpinus cordata | 24.74 | 7075 | 5.1121 | 51.9 |
| ACMA | 白牛槭Acer mandshuricum | 24.59 | 6530 | 5.7088 | 78.3 |
| TIAM | 紫椴Tilia amurensis | 22.49 | 1955 | 11.902 | 102 |
| ACBA | 簇毛槭Acer barbinerve | 20.88 | 8408 | 0.7765 | 11.8 |
| PIKO | 红松Pinus koraiensis | 17.72 | 1302 | 9.274 | 95.1 |
| COMA | 毛榛Corylus mandshurica | 15.97 | 6029 | 0.3006 | 11.5 |
| BECO | 枫桦Betula costata | 13.93 | 818 | 7.3296 | 94.5 |
| SYRE | 暴马丁香Syringa reticulata var. amurensis | 13.01 | 3230 | 0.8869 | 65.7 |
| JUMA | 胡桃楸Juglans mandshurica | 11.17 | 824 | 5.3569 | 77.8 |
| ACTE | 青楷槭Acer tegmentosum | 10.51 | 1809 | 1.9981 | 67 |
| PHAM | 黄檗Phellodendron amurense | 9.61 | 815 | 3.7175 | 62.5 |
| SOAL | 水榆花楸Sorbus alnifolia | 9.36 | 1038 | 2.361 | 80.8 |
| ACUK | 花楷槭Acer ukurunduense | 8.61 | 1990 | 0.771 | 28.1 |
| ABHO | 沙松Abies holophylla | 7.51 | 681 | 2.957 | 105.4 |
| FRMA | 水曲柳Fraxinus mandshurica | 6.15 | 410 | 2.6819 | 84 |
| QUAM | 蒙古栎Quercus mongolica | 4.31 | 153 | 2.5987 | 114.5 |
| ULMA | 大果榆Ulmus macrocarpa | 1.89 | 205 | 0.7487 | 65.7 |
| BEDA | 黑桦Betula dahurica | 1.68 | 74 | 0.9521 | 91.2 |
| TIMA | 糠椴Tilia mandshurica | 1.12 | 104 | 0.5277 | 57.3 |
| ULDA | 春榆Ulmus davidiana Planch. var. japonica | 0.73 | 83 | 0.1465 | 71 |
| POKO | 香杨Populus koreana | 0.44 | 39 | 0.2047 | 59 |
| PODA | 山杨Populus davidiana | 0.29 | 12 | 0.1498 | 71 |
| BEPL | 白桦Betula platyphylla | 0.25 | 28 | 0.0509 | 57.4 |
| FRRH | 花曲柳Fraxinus rhynchophylla | 0.16 | 16 | 0.0529 | 44.6 |
| ABNE | 臭松Abies nephrolepis | 0.04 | 2 | 0.0179 | 44.9 |
| — | 其它others | 16.83 | 2602 | 0.7419 | — |
综合考虑样地面积大小与模型需求, 将样地按照5m×5m、10m×10m、20m×20m、25m×25m大小进行划分, 分别得到12000、3000、750、480个取样单元。在4个尺度下分别统计各物种在每个取样单元中的有无, 得到每个物种在不同尺度下的取样单元数, 并统计在各个尺度下每个物种所占据的所有取样单元的总面积。然后利用随机分布模型和负二项分布模型计算多度的预测值。将预测多度和观测多度进行对比, 获取最优模型。文中数据分析利用R软件完成。
1.3.1 随机分布模型Kunin基于点位图, 提出一个刻画物种多度尺度变化的方法。该方法与分形几何思路一致, 称为尺度-面积法(Scale-area)[16]。作者以英国稀有植物的多度分布数据为例, 通过中、大尺度的物种多度变化规律准确估计出了小尺度的情况。模型形式如下:
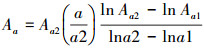
|
式中, a为取样单元面积; Aa为在小尺度取样单元面积为a时, 某物种所占据所有取样单元的面积; Aa1, Aa2为在大尺度取样单元面积为a1, 中尺度取样单元面积为a2时, 某物种分别占据的所有取样单元的面积。
该方法提供了一种通过大尺度数据估计某些小尺度分布特征的方法, 但理论基础相对比较薄弱, 而且生态学解释略显牵强。He和Gaston发现, 该方法总是高估小尺度上的整体占据面积, 可能并不是拟合尺度-面积关系的最佳模型[17]。随着图形比例尺和预测尺度范围的增大, 物种多度格局远离分形, 从而导致预测精度出现下降。因此, 他们提出利用随机分布模型来估计物种多度的方法。该模型的零假设条件为:有N个植物个体随机分布在M个取样单元内, a表示取样单元的面积, A表示整个研究区的面积, 那么A=aM。基于此可以得到在个体服从随机分布时, N的估计值:
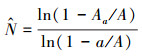
|
式中, N为一个物种在整个研究区中的总个体数; a为取样单元面积; Aa为一个物种在研究区中所占据的所有取样单元的总面积; A为整个研究区的面积。
1.3.2 负二项分布模型在自然界中, 除了某些多度极低的物种, 大多数物种的个体是服从聚集分布的。用来描述聚集分布的模型有泊松分布以及负二项分布等, 其中负二项分布模型最常用来描述物种聚集性。基于此, He和Gaston提出了用负二项分布模型来估计物种多度的方法[17]。其公式形式如下:
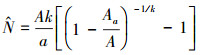
|
式中, N为一个物种在整个研究区中的总个体数; a为取样单元面积; Aa为一个物种在研究区中所占据的所有取样单元的总面积; A为整个研究区的面积; k为一个物种在研究区中的聚集度。
1.3.3 模型评价指标
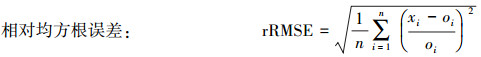
|
相对均方根误差rRMSE是用来衡量观测值同真值之间的偏差。rRMSE越小, 模型预测效果越好。

|
R2值越接近1, 模型预测结果越准确。
式中, xi为物种i的多度预测值, oi为物种i的多度观测值, 
本文在30hm2大面积监测样地中, 利用随机分布模型在不同尺度下计算物种的预测多度, 并将预测多度与观测多度进行对比分析。结果显示在5m×5m、10m×10m、20m×20m、25m×25m四个研究尺度下, 物种的预测多度都不大于观测多度, 并且随着研究尺度的增大, 预测多度与观测多度的差异逐渐增大(图 2)。

|
| 图 2 利用随机分布模型预测不同尺度下的物种多度 Fig. 2 The random distribution model was used to predict species abundance at different scales 实线表示物种预测多度等于观测多度 |
为了检验模型的尺度效应, 采用决定系数(R2)和相对均方根误差(rRMSE)对模型进行优度评价, 结果如表 2所示。随机分布模型的相对均方根误差随着研究尺度的增大逐渐增大, 在5m×5m取样单元下rRMSE值为0.30, 而在25m×25m取样单元下rRMSE值增加到0.50。决定系数随着研究尺度的增大逐渐减小, 在5m×5m取样单元下R2值为0.60, 而在25m×25m取样单元下R2值仅为0.16。因此, 研究尺度越大, 模型的预测效果越差。
| 尺度Scale | rRMSE | R2 | 尺度Scale | rRMSE | R2 | |
| 5m×5m | 0.30 | 0.60 | 20m×20m | 0.48 | 0.22 | |
| 10m×10m | 0.38 | 0.41 | 25m×25m | 0.50 | 0.16 | |
| rRMSE:相对均方根误差relative Root Mean Squared Error; R2:决定系数coefficient of determination | ||||||
利用负二项分布模型计算各个物种在不同尺度下的预测多度, 并将预测多度与观测多度进行对比分析, 结果如图 3所示。在5m×5m的尺度下, 模型的预测效果最好, 随着尺度的增大, 同随机分布模型一样, 预测多度与观测多度的差距逐渐增大, 模型的预测效果也变得越差。因此, 无论是随机分布模型还是负二项分布模型, 在大尺度下模型的预测效果都相对较差。

|
| 图 3 利用负二项分布模型预测不同尺度下的物种多度 Fig. 3 The negative binomial distribution model was used to predict species abundance at different scales 实线表示物种预测多度等于观测多度 |
利用决定系数(R2)和相对均方根误差(rRMSE)检验负二项分布模型的拟合效果(表 3)。在5m×5m取样单元下rRMSE值为0.26, 相对均方根误差随着研究尺度的增大而逐渐增大, 在25m×25m取样单元下rRMSE值达到0.41。R2值随着研究尺度的增大而逐渐减小, 在5m×5m取样单元下R2值为0.89, 而在25m×25m取样单元下R2值下降到0.48。
| 尺度Scale | rRMSE | R2 | 尺度Scale | rRMSE | R2 | |
| 5m×5m | 0.26 | 0.89 | 20m×20m | 0.40 | 0.65 | |
| 10m×10m | 0.33 | 0.78 | 25m×25m | 0.41 | 0.48 |
对比随机分布模型与负二项分布模型的模型效果评价指标。负二项分布模型的相对均方根误差在全部尺度上均小于随机分布模型, 而R2值均大于随机分布模型。因此, 负二项分布模型的预测效果要大大优于随机分布模型。但两种模型均显示, 模型的预测效果随着研究尺度的增加而下降(图 4)。

|
| 图 4 随机分布模型和负二项分布模型评价指标的比较 Fig. 4 Comparison of evaluation indexes between random distribution model and negative binomial distribution model |
全球范围内物种分布数据越来越多地被记录[18], 应用于确定物种濒危状况[19-20], 评估气候和土地利用变化对物种多样性的影响[21-22]。物种分布数据有助于了解物种的时空格局, 预测环境变化和人类活动对物种的影响。除此之外, 预知物种多度的状况也会大大改进我们的研究和实践能力。目前一个具有挑战性的问题是如何估计区域或全球范围内的物种多度, 以便降低在模拟物种分布和评估其对环境变化响应方面的不确定性, 任何关于物种多度的数据甚至是近似值, 都能增强生态推断和预测的能力[23]。在从分布估计多度方面做了很大的努力, 但在估计的精度和实际适用性方面仍存在巨大的提升空间[16-17, 24-28]。
通过对比随机分布模型和负二项分布模型, 发现随机分布模型对物种多度的预测能力较差, 预测值总是小于观测值。这与He等利用随机分布模型对马来西亚50hm2热带雨林样地中的所有物种多度的预测结果一致[17]。将样地划分成不同大小的取样单元, 利用随机分布模型预测不同尺度上的物种多度, 在各个尺度上随机分布模型都会低估物种的观测多度, 并且随着尺度的增大预测多度越来越远离观测多度, 表明尺度越大模型的预测效果越差。Yin等将实验样地划分成不同大小的尺度, 利用随机分布模型对物种多度进行预测, 得到了与本文一致的结果[23]。此外, Hwang等的研究也得到了类似的结论[24]。
除少数多度极低的物种外, 自然界中大多数物种的个体呈现聚集分布[29], 因此随机分布并不是预测物种多度的最佳模型。用来描述聚集分布的泊松分布、负二项分布等, 尤其是负二项分布模型对聚集性分布的物种表现出极强的预测能力[30]。本文采用负二项分布模型对样地中所有物种多度进行拟合, 发现随尺度的增大模型预测的误差也逐渐增大, 但预测效果较随机分布模型有显著提高。Yin等的研究也证实了这一结论[23]。但与之不同的是, 本研究在取样单元为5m×5m时R2最大也不超过0.9。而Yin等的研究中, 在取样单元大小为10m×10m时R2均在0.9以上[23], 这可能是由于其选用的样地面积普遍在50hm2以上, 远大于本研究的样地面积。
在物种多度较小时两种模型的预测精度并无很大差异; 在物种多度较大时(如簇毛槭观测多度为8404、千金榆观测多度为7075), 两种模型的预测误差相对较大。这表明在对分布较为分散的物种进行预测时, 物种所占取样单元数接近物种个体数, 此时的预测精度较高。与之相反, 当物种的分布越集中, 所占取样单元数越偏离物种的个体数, 此时预测误差也就越大。卢辰宇等在灵空山自然保护区油松辽东栎林的研究中也得到了类似的结论[2]。另外, 模型的预测精度表现出显著的尺度依赖性, 在取样单元大小为20m×20m和25m×25m时, 两种模型的预测效果均比较差。在取样单元大小为5m×5m和10m×10m时, 负二项分布模型呈现出极强的预测能力。因此, 应用随机分布和负二项分布模型拟合多度数据, 在样地总面积一定的情况下, 取样单元面积越小时模型的预测精度越高; 在取样单元大小一定的情况下, 样地总面积越大时模型的预测精度也越高。本研究虽然证实负二项分布模型具有更高的预测精度, 但白牛槭、千金榆、簇毛槭和毛榛在所有尺度下预测偏差都较大, 可能是由负二项分布模型未考虑物种的潜在空间自相关导致的。同一样地中树木空间分布的生境关联分析显示, 预测偏差较大的这四个树种在小距离尺度上呈显著空间正自相关, 在较大距离尺度上呈显著空间负自相关[31]。未来需将空间自相关作为影响模型预测效果的一个重要因素进行讨论。负二项分布模型对红松、色木槭、裂叶榆、紫椴、胡桃楸等优势树种多度均能进行较好地预测, 且预测效果优于随机分布模型。而对于其它伴生种, 负二项分布模型均能较好地预测多度, 且预测效果要好于优势种。总的来说, 负二项分布模型均能较好地预测树种的多度, 且预测效果均优于随机分布模型。此外样地面积大小也是影响预测效果的重要因素, 今后应该在考虑上述几个因素的基础上做深入研究。
| [1] |
马克明. 物种多度格局研究进展. 植物生态学报, 2003, 27(3): 412-426. DOI:10.3321/j.issn:1005-264X.2003.03.018 |
| [2] |
卢辰宇, 郭东罡, 张婕, 上官铁梁, 刘卫华, 侯博, 王治明, 李润强. 灵空山自然保护区油松-辽东栎林多度-面积关系分析. 安徽农业科学, 2012, 40(27): 13456-13459. DOI:10.3969/j.issn.0517-6611.2012.27.087 |
| [3] |
谢晋阳, 陈灵芝, Ghirelli L, Chiesura Lorenzoni F. 意大利威尼托大区刺叶栎林的生物多样性研究. 植物学报, 1995, 37(5): 386-393. |
| [4] |
马克平, 刘灿然, 于顺利, 王巍. 北京东灵山地区植物群落多样性的研究Ⅲ. 几种类型森林群落的种-多度关系研究. 生态学报, 1997, 17(6): 573-583. |
| [5] |
朱强, 艾训儒, 姚兰, 朱江, 彭宗林. 鄂西南亚热带山地常绿落叶阔叶混交林物种多度分布格局. 西北植物学报, 2020, 40(6): 1061-1069. |
| [6] |
张金屯. 美国纽约州阔叶林物种多度格局的研究. 植物生态学报, 1999, 23(6): 481-489. DOI:10.3321/j.issn:1005-264X.1999.06.001 |
| [7] |
钟雄, 张敏, 尹茜, 蔡京勇, 汪洋. 野三关红椿天然群落物种多度分布分析. 林业调查规划, 2018, 43(3): 63-67. DOI:10.3969/j.issn.1671-3168.2018.03.012 |
| [8] |
殷祚云, 廖文波. 南亚热带森林群落种-多度的对数正态分布模型研究. 广西植物, 1999(3): 221-224. DOI:10.3969/j.issn.1000-3142.1999.03.008 |
| [9] |
石培礼, 李文华, 王金锡, 刘兴良. 四川卧龙亚高山林线生态交错带群落的种-多度关系. 生态学报, 2000, 20(3): 384-389. DOI:10.3321/j.issn:1000-0933.2000.03.006 |
| [10] |
坤杜孜·萨塔尔, 吕光辉, 蒋腊梅, 王恒方, 王金龙. 艾比湖荒漠植物物种多度分布格局的尺度效应. 干旱区研究, 2020, 37(5): 1273-1283. |
| [11] |
余世孝, 臧润国, 蒋有绪. 海南岛霸王岭不同热带森林类型的种-个体关系. 植物生态学报, 2001, 25(3): 291-297. DOI:10.3321/j.issn:1005-264X.2001.03.006 |
| [12] |
李旭光, 何维明, 王金锡. 绵阳官司河流域防护林物种多样性特征. 西南师范大学学报: 自然科学版, 1996, 21(4): 360-367. |
| [13] |
王文颖, 王启基, 邓自发. 青海海北地区高山嵩草草甸植物群落的结构特征及其分布格局. 植物生态学报, 1998, 22(4): 336-343. DOI:10.3321/j.issn:1005-264X.1998.04.007 |
| [14] |
吴承祯, 洪伟, 郑群瑞. 福建万木林保护区观光木群落物种相对多度模型的拟合研究. 热带亚热带植物学报, 2001, 9(3): 235-242. DOI:10.3969/j.issn.1005-3395.2001.03.011 |
| [15] |
张雪皎, 高贤明, 吉成均, 康慕谊, 王仁卿, 岳明, 张峰, 唐志尧. 中国北方5种栎属树木多度分布及其对未来气候变化的响应. 植物生态学报, 2019, 43(9): 774-782. |
| [16] |
Kunin W E. Extrapolating species abundance across spatial scales. Science, 1998, 281(5382): 1513-1515. DOI:10.1126/science.281.5382.1513 |
| [17] |
He F L, Gaston K J. Estimating species abundance from occurrence. The American Naturalist, 2000, 156(5): 553-559. DOI:10.1086/303403 |
| [18] |
Jetz W, McPherson J M, Guralnick R P. Integrating biodiversity distribution knowledge: toward a global map of life. Trends in Ecology & Evolution, 2012, 27(3): 151-159. |
| [19] |
Cardillo M, Mace G M, Gittleman J L, Jones K E, Bielby J, Purvis A. The predictability of extinction: biological and external correlates of decline in mammals. Proceedings of the Royal Society B: Biological Sciences, 2008, 275(1641): 1441-1448. DOI:10.1098/rspb.2008.0179 |
| [20] |
He F L. Area-based assessment of extinction risk. Ecology, 2012, 93(5): 974-980. DOI:10.1890/11-1786.1 |
| [21] |
Thomas C D, Cameron A, Green R E, Bakkenes M, Beaumont L J, Collingham Y C, Erasmus B F N, de Siqueira M F, Grainger A, Hannah L, Hughes L, Huntley B, van Jaarsveld A S, Midgley G F, Miles L, Ortega-Huerta M A, Peterson A T, Phillips O L, Williams S E. Extinction risk from climate change. Nature, 2004, 427(6970): 145-148. DOI:10.1038/nature02121 |
| [22] |
Jetz W, Wilcove D S, Dobson A P. Projected impacts of climate and land-use change on the global diversity of birds. PLoS Biology, 2007, 5(6): 157. DOI:10.1371/journal.pbio.0050157 |
| [23] |
Yin D Y, He F L. A simple method for estimating species abundance from occurrence maps. Methods in Ecology and Evolution, 2014, 5(4): 336-343. DOI:10.1111/2041-210X.12159 |
| [24] |
Hwang W H, He F L. Estimating abundance from presence/absence maps. Methods in Ecology and Evolution, 2011, 2(5): 550-559. DOI:10.1111/j.2041-210X.2011.00105.x |
| [25] |
Conlisk E, Conlisk J, Enquist B, Thompson J, Harte J. Improved abundance prediction from presence-absence data. Global Ecology and Biogeography, 2009, 18(1): 1-10. DOI:10.1111/j.1466-8238.2008.00427.x |
| [26] |
Hui C, McGeoch M A, Reyers B, Roux P C, Greve M, Chown S L. Extrapolating population size from the occupancy-abundance relationship and the scaling pattern of occupancy. Ecological Applications, 2009, 19(8): 2038-2048. DOI:10.1890/08-2236.1 |
| [27] |
Solow A R, Smith W K. On predicting abundance from occupancy. The American Naturalist, 2010, 176(1): 96-98. DOI:10.1086/653077 |
| [28] |
Azaele S, Cornell S J, Kunin W E. Downscaling species occupancy from coarse spatial scales. Ecological Applications, 2012, 22(3): 1004-1014. DOI:10.1890/11-0536.1 |
| [29] |
McArdle B H, Gaston K J, Lawton J H. Variation in the size of animal populations: patterns, problems and artefacts. Journal of Animal Ecology, 1990, 59(2): 439-454. DOI:10.2307/4873 |
| [30] |
Perry J N, Taylor L R. Ade`s: new ecological families of species-specific frequency distributions that describe repeated spatial samples with an intrinsic power-law variance-mean property. Journal of Animal Ecology, 1985, 54(3): 931-953. DOI:10.2307/4388 |
| [31] |
丁胜建, 张春雨, 夏富才, 赵秀海, 倪瑞强, 范娟, 何怀江. 老龄阔叶红松林下层木空间分布的生境关联分析. 生态学报, 2012, 32(11): 3334-3342. |