 2023, Vol. 43
2023, Vol. 43文章信息
- 林婴伦, 李春明, 王静怡, 翁辰, 焦亚冉
- LIN Yinglun, LI Chunming, WANG Jingyi, WENG Chen, JIAO Yaran
- 基于多传感器的声景大数据在线采集与分析系统研究
- The soundscape big data online capturing and analysis system based on multi-sensor
- 生态学报. 2023, 43(4): 1474-1484
- Acta Ecologica Sinica. 2023, 43(4): 1474-1484
- http://dx.doi.org/10.5846/stxb202112283687
-
文章历史
- 收稿日期: 2021-12-28
- 网络出版日期: 2022-10-13





2. 中国科学院城市环境研究所, 城市环境与健康重点实验室, 厦门 361021;
3. 厦门市物理环境重点实验室, 厦门 361021;
4. 中国科学院大学, 北京 100049
2. Key Lab of Urban Environment and Health, Institute of Urban Environment, Chinese Academy of Sciences, Xiamen 361021, China;
3. Xiamen Key Laboratory of Physical Environment, Xiamen 361021, China;
4. University of Chinese Academy of Sciences, Beijing 100049, China
声景是指在一定地区内由一系列蕴含不同信息的声元素构成的总体, 是景观的重要组成部分, 包含重要的生态信息。国际标准组织(ISO)将声景定义为人类感知、体验或者理解的声学环境[1], 强调人群的主观感受。声景数据信息密度高, 具有大数据的典型特征, 在声景生态学中, 生物声、地理声和人类声共同构成了完整的声景[2]。越来越多的学者尝试从声景中提取信息, 并在声景质量评价、声景规划、物种识别、生物多样性评估、人类身心健康评价等方面开展研究。
声景质量评价区别传统的仅以声音物理量为要素的噪声评价, 引入声源、用户主观感受指标[3—5], 使得评价结果更符合人们的实际感受, 更为科学, 声景概念的引入, 使得声音被视为一种资源, 学者开始从设计规划方面来改善声环境质量, 出现了大量以城市公共空间, 如居民区[6]、公园[7]、街道[8]为对象的声景设计和规划研究, 然而声景评价、设计和规划的研究往往研究尺度小, 数据采集周期不长, 研究结果难以在大尺度上进行推广和应用。基于声学生态位假说[9]和形态学适应假说[10], 不同的发声生物具有不同的声纹特征[11—12], 学者开始借助声纹特征来进行鸟[13—14]、青蛙[15], 鲸鱼[14]的识别, 并取得了较高的准确率。从声学的角度, 声景也能较好地反映生物之间、生物与周边环境之间的作用关系, 以及生物多样性等信息。如Borker等对有外来物种入侵史岛屿的声景研究发现, 声学丰度指数与入侵捕食者的灭绝时间及其巢穴出现时间有较强的关联性, 且随着捕食者的灭绝呈现上升趋势[16]。Bradfer-Lawrence等通过对巴拿马国内不同地点的录音片段进行标准差异声景指数(NDSI)计算, 发现鸟类丰度较高的地点的声景较不均匀[17], Campos-Cerqueira等通过对不同森林地块里的鸟类丰度和声学空间使用指数(ASU)、声景组成进行对比研究, 发现声音指标不仅数据连续性较好, 还能有效区分不同人类干扰梯度的自然环境[18]。Burivalova等和Sethi等通过对不同地区, 不同时间段的声景特征进行分析, 指出借助声景特征能快速反映生态系统多样性[19—20]。而近年来的研究也发现, 积极的声景对人体的身心健康具有促进作用, 长时间接触自然声音的受访志愿者的健康指标(如皮质醇、血压等)显著优于常接触噪声的受访志愿者[21]。
现有研究案例多以人工、定期、离线的方式获取和分析声景数据, 不仅成本较高、实时性不强, 而且在数据获取时对环境存在一定的干扰, 同时声景具有显著的时空异质性[22], 短期和小范围的调查难以揭示声景的时空变化规律以及生物、环境、人类三者之间的相互作用机制。在2021年12月生态环境部印发的《“十四五”生态环境监测规划》中也明确指出2025年底前地级及以上城市全面实现功能区声环境质量自动监测, 优化声环境质量评价指标与方法, 为此开展长期声景监测研究的需求日益迫切。
通过监测网络连续不断地获取声景大数据, 对及时了解物种和生物多样性的动态变化具有重要作用, 同时可以为区域声景特征的时空变化规律、生物之间以及生物与环境之间的作用关系、声景与人类身心健康的研究提供更加全面和深入的认知, 也和国家的“十四五”生态环境监测发展规划相吻合。本文基于声景大数据在物种识别、生物多样性评估、声景规划、人类身心健康等方面的应用前景, 提出了建立长期、在线、实时声景监测网络的必要性, 并从数据采集与分析两个方面详细阐述了声景监测网络的系统研制技术, 同时以研究案例介绍了系统的实际使用效果, 以期待为声景长期监测网的建设提供参考。
1 研究方法 1.1 硬件系统集成系统硬件分别由位于现场的边缘计算节点和数据中心的中心计算服务器构成(图 1)。其中边缘计算节点主要由4部分构成, 分别是供电单元、传感器单元、数据采集和处理单元, 以及通信单元构成。供电单元可由太阳能或市电提供, 经过降压和稳压电路调理后输出稳定的直流电供系统使用。传感器单元负责感知站点周边声音、图像和环境要素的状态, 主要由传声器(响应频率20—20000 Hz)、图像传感器、气象传感器和系统功率传感器构成, 其中气象传感器包括大气温湿度、光照、气压、总辐照、光合有效辐照、风速、降雨量、土壤温湿度, 这些气象因素对声景结构和变化都有着直接或者间接的影响[23—24]。数据采集与处理单元主要负责进行传感器信号的采集以及采集数据的处理, 由微型电脑构成。通信单元负责数据的远程传输, 可根据现场信号情况选择WIFI或者4G模式进行通信。中心计算服务器负责远程数据的接收、存储和分析计算, 由CPU和GPU服务器构成, 在CPU和GPU上分别搭建了数据服务和数据分析服务。其中, 数据服务负责数据的接收和入库存储, 数据分析服务负责声景数据的分析, 包括声学指数计算、声纹特征提取、声景特征分类。

|
| 图 1 系统硬件结构 Fig. 1 The structure of hardware system MQTT:消息队列遥测传输Message queuing telemetry transport;FTP:文件传输协议File transfer protocol;CPU:中央处理器Central processing unit;GPU:图形处理器Graphic processing unit |
软件程序包括运行在边缘计算节点中的数据采集和传输程序, 以及运行在中心计算服务器中的数据分析程序。边缘计算节点中的数据采集和传输程序采用多线程对气象传感器和系统功率传感器进行定时采集, 采集周期为2分钟。其中气象数据的采集和处理方法依据《地面气象观测规范自动观测(GB/T 35237—2017)》标准进行, 计算出1分钟内的气象平均数值。当气象数据采集完成后, 便进行声音和图像采集, 声音采用44100 Hz, 24 Bit, 单通道的方式采集5秒音频片段, 采用wav格式存放;而图像数据采用500万像素, RGB可见光进行采集, 采用JPG格式存放。气象数据和系统状态数据采集完成后采用标准Json格式进行封装, 并通过MQTT协议发送至远程数据库。声音、图像则采用FTP加密协议传输至远程服务器, 若网络不通则采集的数据暂存于本地, 网络畅通后再传输至远程服务器。边缘节点的数据传输流程如图 2。

|
| 图 2 边缘计算节点程序运行流程图 Fig. 2 Operation flow chart of edge computing node |
声学指数是通过统计声学能量或者频率的分布, 得出声音振幅或者频率的复杂程度、异质性等信息。声学指数在生物声学中被广泛使用, 它能够从音频数据中提取出有用的生态学信息[24—31]。声学指数种类繁多, 典型的包括时间熵(H[t])、频谱熵(H[s])、声学复杂指数(ACI)、声学均匀度指数(AEI)、标准差异声景指数(NDSI), 以及声学多样性指数(ADI), 生物声学指数(BIO)等。不同的声学指数反应不同的生态学信息, 若声音录制点的生态环境不佳、发声物种群单一, 则声景显得更为“贫瘠”, 在各个频带上更加均匀的分布着较低的声能[16, 32]。声学指数和成熟的生态学指数的强关联性已经在先前的研究中被证实[16, 17, 29, 33]。
相关的研究证明, 声学指数的组合相比于单个声学指数能更好地预测采样点的生物多样性指数, 如物种丰度等[29, 33]。这表明声学指数的组合相比于单个声学指数能蕴含更多的环境信息。本系统对常用的声学指数(表 1)进行了实现, 当声音文件被采集回传后, 系统实时计算并输出结果。
| 名称Name | 含义Meaning |
| 声学熵指数Total entropy [28] | 时间熵和频谱熵的乘积, 评估声信号在时频域上的均匀度和复杂度 |
| 声学复杂指数Acoustic complexity [31] | 将频谱划分特定数量的帧, 计算其相邻帧的声强差之和和声强之和的比值, 用于表述声强的变异性 |
| 声学均匀度指数Acoustic evenness index [32] | 将频谱划分特定数量的帧, 取其声强高于特定阈值的帧, 计算其基尼系数 |
| 标准差异声景指数Normalized difference soundscape index [27] | 声音样本中发现的人为与生物(生物声音)声学成分的比率 |
| 声学多样性指数Acoustic diversity index [32] | 将频谱划分特定数量的帧, 取其声强高于特定阈值的帧, 计算其香农指数 |
| 生物声学指数Bioacoustic index [30] | 音频的声强-频率图中范围从2000 Hz到8000 Hz的积分 |
声纹特征是指特定声音的频谱图片段。根据声学生态位假说、形态学适应假说, 不同的物种具有不同的声纹特征, 在物种音频分类任务中常作为输入特征[34—37]。频谱图是音频频谱随时间变化的直观表示, 在音频分析中被广泛使用, 采用梅尔刻度的频谱图被称作梅尔频谱图[37]。线性的赫兹标度(Fhertz)被映射到梅尔标度(Fmel)后, 更能客观的模拟人耳对不同频率声音感知的差异, 映射公式如1。
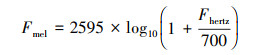
|
(1) |
本系统对所采集的音频片段进行梅尔频谱图计算和绘制, 使用Librosa程序包里面的函数生成。具体关键生成参数如下:使用长度为1024的汉宁窗口, 连续帧之间的重叠率为50%, 梅尔波段个数设置为128, 以采样率的一半进行缩放。
1.3.3 声景特征分类随着神经网络等深度学习算法的兴起, 计算机对音频的处理以及特征挖掘能力进一步增强, 不同于声学指数以音频振幅、频率、峰值等一维变量计算。神经网络所提取的高维特征是以任务为导向学习而来, 通过反向梯度传播不断调整和计算内部节点之间相互连接的关系, 从而完成信息的处理。尽管神经网络输出的语义特征难以解释, 但往往有着非常好的表达性、预测性[38—39]。
Google公司于2017年发布了大型音频数据集Audioset[40]。数据集包含200万余条人工标记的10秒段长的音频片段, 标记的标签达527类, 涵盖大部分人类已知的声音种类。在此基础上, 此团队以VGG-11[41](Visual Geometry Group)结构为基线使用此数据集进行训练得到了类VGG预训练模型[42], 后被命名为VGGish。除了输入图片的大小由224×224变为96×64以及输出维度由1000维变为128维以外, VGGish的模型结构和VGG-11并没有太大的差别。VGGish基于Audioset大数据集的优势能得到表达较好的特征。Shi等人将VGGish和双向循环神经网络(BiGRU)相结合, 提出了一种VGGish-BiGRU的肺音识别算法, 能够识别肺炎、哮喘患者以及健康人三种肺音, 总体准确率可达87%[43]。本系统采取VGGish预训练模型作为声音特征提取模型, 将音频样本的声纹特征逐个输入具有11个权重层的VGGish预训练模型中, 每个1秒音频片段将生成128×1形状的特征。再将特征拼接后以取均值的方式向下采样为128维特征(图 3)。

|
| 图 3 VGGish网络结构和声景特征提取 Fig. 3 Structure of VGGish network and soundscape feature extraction |
为了直观地呈现神经网络输出的128维特征空间, 进一步通过流形数据降维工具UMAP(Uniform Manifold Approximation and Projection for Dimension Reduction)将高维特征降至二维特征平面, 以此直观地呈现声景特征的分类可视化效果, 旨在揭示声景在时间(季节与昼夜)、空间(不同生境)的结构特征。同时为了评估128维特征在不同时空尺度上的声景特征的分类能力, 将128维声景特征输入到随机森林模型中执行不同的声景特征分类任务, 并通过5折交叉验证的准确率来体现声景特征的分类能力(图 4), 即将数据随机分成5份, 用4份作为训练集采用随机森林建模, 验证另外1份的分类精度, 重复上述步骤, 让每一份数据都充当一次验证集, 统计平均准确率(公式2)。
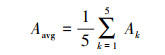
|
(2) |

|
| 图 4 声景特征提取和分类准确率验证 Fig. 4 Features extraction and classification accuracy verification of soundscape |
式中, Aavg代表 5折交叉验证的平均分类准确率, Ak代表第k折时的训练出来的随机森林的对测试集的分类准确率。
2 研究案例 2.1 站点布设情况系统研制完成后进行了声景监测网的实地布设(图 5), 站点选取时设置了环境差异梯度, 1号站点(IUE001)靠近交通主干道, 2号站点(IUE002)位于城市树林中的水体旁, 3号站点(IUE003)靠近城市支路, 车流量较少。目前系统已经连续稳定运行了300余天, 累计采集数据160万余条。

|
| 图 5 声景在线监测网及3号站点 Fig. 5 Soundscape online monitoring network and the number 3 station |
节选系统采集的数据, 展示系统在声学指数计算、声纹特征提取和声景特征分类方面的分析结果。
2.2.1 声学指数计算结果本文选取了系统计算的2021年8月2日这天24小时的6个声学指数(图 6)。从站点的角度来看, 3个站点在相同时间段都表现出相似的趋势, 这是由于3个站点的在空间位置上较近, 不同站点的发声物种的类型相似所致。但是站点之间夜晚存在差异, 尤其是IUE002号点在20:00—05:00声学指数(BIO、ADI、AEI、NDSI)与其他站点差异较大, 这主要是由不同地点的生境特征、生物种类(如昆虫种类)、背景噪声等微观结构不同导致的。

|
| 图 6 不同声学指数日变化 Fig. 6 Daily variation of various acoustic index IUE: 站点标识名 |
从不同时间段来看, 除了声学复杂指数外, 其它3个站点在白昼的时候变化波动较大而在夜晚的时候变化趋于平缓。这是由白昼声源类型繁多, 如人声、车流声、鸟声等, 夜晚多为连续不断的虫鸣和车流声, 声源结构单一所致。同时, 不同的声学指数由于其计算的方式不一样, 所以呈现的时间变化规律不一致, 因此声学指数往往需要组合应用才能更好地解释背后的变化原因。
2.2.2 声纹特征提取结果从2021年8月2日3个站点8:30(白昼)和22:30(夜晚)的声纹图中, 能够清晰分辨出不同的声音事件(图 7)。白昼时, 3个站点声源类型较多, 如蝉鸣、鸟叫、车流声、异常声。夜晚时, 声源类型较为单一。这也解释了声学指数在白天的时候波动较大, 夜晚比较平缓的原因。IUE001站点相比于IUE002和IUE003更靠近交通主干道, 受到主干道车流低频噪声影响更大, 从3个站点不同频率声强分布也可以直观地反映出该差别。可见用声纹特征图能较好地甄别出声场内的各类声音事件。

|
| 图 7 站点典型梅尔频谱图 Fig. 7 Typical mel spectrogram of the stations |
选取2021年8月份3个站点的音频数据进行声景特征提取和可视化分类, 每个站点共计22320个音频片段(共计11150秒)。从图 8可以看出降维后不同站点的声景特征区分度较好, 特别是IUE002与IUE001, IUE003站点的声景特征中心点距离较远, 表明声景特征能较好地区分出不同的生境特征, 具有判别站点周围生态结构及物种多样性的潜力。从图 8可以看出声景特征在以小时为尺度的分离性和聚集性不是太好, 这是由于同一站点的声景在较短时间内差异较小。但是白昼(06:00—18:00)和夜晚(18:00—06:00)呈现明显的分离状态, 特别是IUE002号站点白昼和夜晚差异明显, 表明基于VGGish提取的声景特征有实时反映站点周边生态系统动态变化的能力。

|
| 图 8 声景特征可视化结果 Fig. 8 Visualization of soundscape features |
为了评估VGGish网络提取的特征对不同时间尺度和空间声景的分类能力, 将声景特征作为输入, 使用随机森林模型作为分类器进行5折交叉训练验证, 计算其准确率。分别以白昼-夜晚时间尺度, 小时时间尺度, 站点作为分类标签得到表 2分类结果。
| 输入特征 Input features |
标签 Label |
5折交叉验证平均准确率 Average accuracy of 5-fold cross validation |
| 3个站点8月128维声景特征 128 dimension features of 3 sites in August |
站点 | 0.921 |
| IUE001的8月128维声景特征 128 dimension features of IUE001 in August |
时 | 0.232 |
| IUE002的8月128维声景特征 128 dimension features of IUE002 in August |
时 | 0.398 |
| IUE003的8月128维声景特征 128 dimension features of IUE003 in August |
时 | 0.233 |
| IUE001的8月128维声景特征 128 dimension features of IUE001 in August |
白昼-夜晚 | 0.856 |
| IUE002的8月128维声景特征 128 dimension features of IUE002 in August |
白昼-夜晚 | 0.926 |
| IUE003的8月128维声景特征 128 dimension features of IUE003 in August |
白昼-夜晚 | 0.841 |
| 白昼-夜晚代表以白昼(06:00—18:00), 夜晚(18:00—06:00)标注数据 | ||
当以站点白昼-夜晚作为标签时分类器的预测精确度明显优于以小时为标签, 同时发现IUE002站点的以24小时和白昼-夜晚作为标签时的交叉验证精确度明显高于其它两个站点。这是由于IUE002站点位于树林的湖边受到人类的干扰程度较小, 白昼夜晚声源差异较大所致。
3 结论与展望本文基于多传感器集成、边缘计算和深度学习技术, 建立了一套声景大数据在线采集与分析系统, 并布设了3个实验站点, 进行了近一年的技术验证, 得出了以下结论:
(1) 研制的系统稳定性好, 能根据任务需求持续不断进行声景大数据的在线采集和分析, 能适应户外恶劣的自然环境(如暴雨和高温)。系统能快速地实现声学指数计算、声纹特征提取、声景特征分类等计算业务, 能为声景大数据的在线采集和分析提供详细的参考。
(2) 通过分析系统计算的3个站点的不同声学指数的变化趋势, 发现声学指数可以反映声景的变化特征, 但不同的声学指数之间的变化特征差异较大, 同时声学指数多是以声音振幅、频率等物理性质作为计算参数, 信息维度单一, 存在对偶发异常事件抗干扰能力差的缺点, 在使用时需要组合;通过声纹特征图能较好地识别出不同发声源, 对物种的快速识别、声源的分类等具有较强的借鉴意义;系统借助VGGish网络提取的高维声景特征图能很好地区分不同站点和不同时间的声景变化, 具备快速和直观地反映不同生态系统的类型、生态系统动态变化的潜力。
(3) 目前系统声景特征的提取模型是基于AudioSet数据集, 尽管是目前世界上规模最大的声学特征库, 但也存在声纹特征不平衡问题。在未来的研究中还可以从结合站点周边环境参数、完善声纹标记方法、丰富声纹特征库、优化声景特征分析神经网络、建设声景长期监测共享网络等角度开展深入研究, 不仅能形成我国特有的声景特征库和声景监测网络, 也能进一步扩展系统在物种识别、生物多样性快速分析、生物与环境相互作用机制方面的应用。
| [1] |
ISO/TC 43/SC 1 Noise Technical Committee. 12913-1: 2014 Acoustics-Soundscape-Part 1: Definition and Conceptual Framework. Geneva. Switzerland: International Organization for Standardization; 2014.
|
| [2] |
Pijanowski B C, Villanueva-Rivera L J, Dumyahn S L, Farina A, Krause B L, Napoletano B M, Gage S H, Pieretti N. Soundscape ecology: the science of sound in the landscape. BioScience, 2011, 61(3): 203-216. DOI:10.1525/bio.2011.61.3.6 |
| [3] |
Jeon J Y, Lee P J, You J, Kang J. Perceptual assessment of quality of urban soundscapes with combined noise sources and water sounds. The Journal of the Acoustical Society of America, 2010, 127(3): 1357-1366. DOI:10.1121/1.3298437 |
| [4] |
Kang J, Zhang M. Semantic differential analysis of the soundscape in urban open public spaces. Building and Environment, 2010, 45(1): 150-157. DOI:10.1016/j.buildenv.2009.05.014 |
| [5] |
Yang W, Kang J. Acoustic comfort evaluation in urban open public spaces. Applied Acoustics, 2005, 66(2): 211-229. DOI:10.1016/j.apacoust.2004.07.011 |
| [6] |
Gidl f-Gunnarsson A, Öhrstr m E. Noise and well-being in urban residential environments: the potential role of perceived availability to nearby green areas. Landscape and Urban Planning, 2007, 83(2/3): 115-126. |
| [7] |
Jeon J Y, Hong J Y. Classification of urban park soundscapes through perceptions of the acoustical environments. Landscape and Urban Planning, 2015, 141: 100-111. DOI:10.1016/j.landurbplan.2015.05.005 |
| [8] |
Raimbault M, Dubois D. Urban soundscapes: experiences and knowledge. Cities, 2005, 22(5): 339-350. DOI:10.1016/j.cities.2005.05.003 |
| [9] |
B Krause. The Niche Hypothesis: A virtual symphony of animal sounds, the origins of musical expression and the health of habitats. Soundscape Newsletter (World Forum for Acoustic Ecology), 1993, 6: 6-10. |
| [10] |
Seddon N. Ecological adaptation and species recognition drives vocal evolution in neotropical suboscine birds. Evolution, 2005, 59(1): 200-215. |
| [11] |
李东风, 张丹荔. 野生虎皮鹦鹉与家养虎皮鹦鹉鸣声比较和声谱分析. 辽宁师范大学学报: 自然科学版, 2021, 44(2): 214-221. |
| [12] |
蒋锦刚, 邵小云, 万海波, 齐家国, 荆长伟, 程天佑. 基于语谱图特征信息分割提取的声景观中鸟类生物多样性分析. 生态学报, 2016, 36(23): 7713-7723. |
| [13] |
Somervuo P, Harma A, Fagerlund S. Parametric representations of bird sounds for automatic species recognition. IEEE Transactions on Audio, Speech, and Language Processing, 2006, 14(6): 2252-2263. DOI:10.1109/TASL.2006.872624 |
| [14] |
Nanni L, Aguiar R L, Costa Y M G, Brahnam S, Silla Jr C N, Brattin R L, Zhao Z. Bird and whale species identification using sound images. IET Computer Vision, 2018, 12(2): 178-184. DOI:10.1049/iet-cvi.2017.0075 |
| [15] |
Alonso J B, Cabrera J, Shyamnani R, Travieso C M, Bolaños F, García A, Villegas A, Wainwright M. Automatic anuran identification using noise removal and audio activity detection. Expert Systems With Applications, 2017, 72: 83-92. DOI:10.1016/j.eswa.2016.12.019 |
| [16] |
Borker A L, Buxton R T, Jones I L, Major H L, Williams J C, Tershy B R, Croll D A. Do soundscape indices predict landscape-scale restoration outcomes? A comparative study of restored seabird island soundscapes. Restoration Ecology, 2020, 28(1): 252-260. DOI:10.1111/rec.13038 |
| [17] |
Bradfer-Lawrence T, Bunnefeld N, Gardner N, Willis S G, Dent D H. Rapid assessment of avian species richness and abundance using acoustic indices. Ecological Indicators, 2020, 115: 106400. DOI:10.1016/j.ecolind.2020.106400 |
| [18] |
Campos-Cerqueira M, Mena J L, Tejeda-Gómez V, Aguilar-Amuchastegui N, Gutierrez N, Aide T M. How does FSC forest certification affect the acoustically active fauna in Madre de Dios, Peru?. Remote Sensing in Ecology and Conservation, 2020, 6(3): 274-285. DOI:10.1002/rse2.120 |
| [19] |
Burivalova Z, Towsey M, Boucher T, Truskinger A, Apelis C, Roe P, Game E T. Using soundscapes to detect variable degrees of human influence on tropical forests in Papua New Guinea. Conservation Biology, 2018, 32(1): 205-215. DOI:10.1111/cobi.12968 |
| [20] |
Sethi S S, Jones N S, Fulcher B D, Picinali L, Clink D J, Klinck H, Orme C D L, Wrege P H, Ewers R M. Characterizing soundscapes across diverse ecosystems using a universal acoustic feature set. Proceedings of the National Academy of Sciences of the United States of America, 2020, 117(29): 17049-17055. DOI:10.1073/pnas.2004702117 |
| [21] |
Buxton R T, Pearson A L, Allou C, Fristrup K, Wittemyer G. A synthesis of health benefits of natural sounds and their distribution in National Parks. Proceedings of the National Academy of Sciences of the United States of America, 2021, 118(14): e2013097118. DOI:10.1073/pnas.2013097118 |
| [22] |
Bian Q, Wang C, Hao Z Z. Application of ecoacoustic monitoring in the field of biodiversity science. Ying Yong Sheng Tai Xue Bao=the Journal of Applied Ecology, 2021, 32(3): 1119-1128. |
| [23] |
杜功焕. 声学基础 (2版). 南京: 南京大学出版社, 2001.
|
| [24] |
杨训仁, 陈宇. 大气声学 (2版). 北京: 科学出版社, 2007.
|
| [25] |
Depraetere M, Pavoine S, Jiguet F, Gasc A, Duvail S, Sueur J. Monitoring animal diversity using acoustic indices: implementation in a temperate woodland. Ecological Indicators, 2012, 13(1): 46-54. DOI:10.1016/j.ecolind.2011.05.006 |
| [26] |
Gasc A, Sueur J, Jiguet F, Devictor V, Grandcolas P, Burrow C, Depraetere M, Pavoine S. Assessing biodiversity with sound: do acoustic diversity indices reflect phylogenetic and functional diversities of bird communities?. Ecological Indicators, 2013, 25: 279-287. DOI:10.1016/j.ecolind.2012.10.009 |
| [27] |
Kasten E P, Gage S H, Fox J, Joo W. The remote environmental assessment laboratory & apos; s acoustic library: an archive for studying soundscape ecology. Ecological Informatics, 2012, 12: 50-67. DOI:10.1016/j.ecoinf.2012.08.001 |
| [28] |
Sueur J, Pavoine S, Hamerlynck O, Duvail S. Rapid acoustic survey for biodiversity appraisal. PLoS One, 2008, 3(12): e4065. DOI:10.1371/journal.pone.0004065 |
| [29] |
Towsey M, Wimmer J, Williamson I, Roe P. The use of acoustic indices to determine avian species richness in audio-recordings of the environment. Ecological Informatics, 2014, 21: 110-119. DOI:10.1016/j.ecoinf.2013.11.007 |
| [30] |
Boelman N T, Asner G P, Hart P J, Martin R E. Multi-trophic invasion resistance in Hawaii: bioacoustics, field surveys, and airborne remote sensing. Ecological Applications, 2007, 17(8): 2137-2144. DOI:10.1890/07-0004.1 |
| [31] |
Pieretti N, Farina A, Morri D. A new methodology to infer the singing activity of an avian community: the Acoustic Complexity Index (ACI). Ecological Indicators, 2011, 11(3): 868-873. DOI:10.1016/j.ecolind.2010.11.005 |
| [32] |
Villanueva-Rivera L J, Pijanowski B C, Doucette J, Pekin B. A primer of acoustic analysis for landscape ecologists. Landscape Ecology, 2011, 26(9): 1233-1246. DOI:10.1007/s10980-011-9636-9 |
| [33] |
Eldridge A, Guyot P, Moscoso P, Johnston A, Eyre-Walker Y, Peck M. Sounding out ecoacoustic metrics: Avian species richness is predicted by acoustic indices in temperate but not tropical habitats. Ecological Indicators, 2018, 95: 939-952. DOI:10.1016/j.ecolind.2018.06.012 |
| [34] |
Briggs F, Lakshminarayanan B, Neal L, Fern X Z, Raich R, Hadley S J K, Hadley A S, Betts M G. Acoustic classification of multiple simultaneous bird species: a multi-instance multi-label approach. The Journal of the Acoustical Society of America, 2012, 131(6): 4640-4650. DOI:10.1121/1.4707424 |
| [35] |
Dong X Y, Towsey M, Zhang J L, Roe P. Compact features for birdcall retrieval from environmental acoustic recordings. 2015 IEEE International Conference on Data Mining Workshop. November 14-17, 2015, Atlantic City, NJ, USA. IEEE, 2015: 762-767.
|
| [36] |
Strout J, Rogan B, Seyednezhad S M M, Smart K, Bush M, Ribeiro E. Anuran call classification with deep learning. 2017 IEEE International Conference on Acoustics, Speech and Signal Processing. March 5-9, 2017, New Orleans, LA, USA. IEEE, 2017: 2662-2665.
|
| [37] |
Thomas M, Martin B, Kowarski K, Gaudet B, Matwin S. Marine mammal species classification using convolutional neural networks and a novel acoustic representation. Machine Learning and Knowledge Discovery in Databases, 2020, 11908: 290-305. |
| [38] |
Cavallari G B, Ribeiro L S F, Ponti M A. Unsupervised representation learning using convolutional and stacked auto-encoders: a domain and cross-domain feature space analysis. 2018 31st SIBGRAPI Conference on Graphics, Patterns and Images (SIBGRAPI). October 29-November 1, 2018, Parana, Brazil. IEEE, 2018: 440-446.
|
| [39] |
Ponti M A, Ribeiro L S F, Nazare T S, Bui T, Collomosse J. Everything You wanted to know about deep learning for computer vision but were afraid to ask. 2017 30th SIBGRAPI Conference on Graphics, Patterns and Images Tutorials (SIBGRAPI-T). October 17-18, 2017, Niteroi, Brazil. IEEE, 2017: 17-41.
|
| [40] |
Gemmeke J F, Ellis D P W, Freedman D, Jansen A, Lawrence W, Moore R C, Plakal M, Ritter M. Audio Set: an ontology and human-labeled dataset for audio events. 2017 IEEE International Conference on Acoustics, Speech and Signal Processing. March 5-9, 2017, New Orleans, LA, USA. IEEE, 2017: 776-780.
|
| [41] |
Simonyan K, Zisserman A. Very Deep Convolutional Networks for Large-Scale Image Recognition. [2022-2-15], https://arxiv.org/pdf/1409.1556.pdf.
|
| [42] |
Hershey S, Chaudhuri S, Ellis D P W, Gemmeke J F, Jansen A, Moore R C, Plakal M, Platt D, Saurous R A, Seybold B, Slaney M, Weiss R J, Wilson K. CNN architectures for large-scale audio classification. 2017 IEEE International Conference on Acoustics, Speech and Signal Processing. March 5-9, 2017, New Orleans, LA, USA. IEEE, 2017: 131-135.
|
| [43] |
Shi L K, Du K, Zhang C Z, Ma H Q, Yan W J. Lung sound recognition algorithm based on VGGish-BiGRU. IEEE Access, 2019, 7: 139438-139449. DOI:10.1109/ACCESS.2019.2943492 |