 2019, Vol. 39
2019, Vol. 39文章信息
- 潘鹤思, 柳洪志
- PAN Hesi, LIU Hongzhi
- 跨区域森林生态补偿的演化博弈分析——基于主体功能区的视角
- The evolutionary game analysis of cross-regional forest ecological compensation-based on the perspective of the main functional area
- 生态学报. 2019, 39(12): 4560-4569
- Acta Ecologica Sinica. 2019, 39(12): 4560-4569
- http://dx.doi.org/10.5846/stxb201809252080
-
文章历史
- 收稿日期: 2018-09-25
- 网络出版日期: 2019-04-01

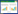




2. 哈尔滨商业大学商业经济研究院, 哈尔滨 150028
2. Harbin University of Commerce, Institute of Business Economics, Harbin 150028, China
森林生态环境是人类生存和社会经济发展的基础, 也是生态文明建设的基本条件。围绕十七大报告精神以及“十一五”规划纲要, 依据区域资源禀赋、自然条件和环境承载力等, 将国土空间划分为优化开发、重点开发、限制开发和禁止开发四类主体功能区。针对限制和禁止开发区, 中央政府明确提出要“实行生态资源有偿使用制度和生态补偿制度”。然而中国目前的实际情况是由中央政府和经济落后的生态功能区来承担生态环境保护的责任, 而经济发展较快的优化开发区和重点开发区在没有任何生态投入的情况下享受外溢生态服务, 生态补偿资金来源单一且规模较小, 不足以弥补生态功能区放弃资源开发的机会成本和生态恢复的治理成本, 导致当地政府和居民缺乏生态环境保护的积极性, 国家生态保护的目标难以真正落实。因此在森林生态保护的过程中, 考虑多主体的利益驱动、决策依据以及主体间的交互作用, 构建基于中央政府“约束-激励”管制下的地区政府间互动合作的内生机制, 是实现森林生态环境优化的关键举措。
生态资源具有公共资源和公共物品的特性, 人们对生态资源的利用会造成个人边际成本和社会边际成本不相等现象[1], 生态补偿机制就是通过调节相关方的利益关系, 将生态服务外部效应内化, 体现公平公正的原则, 然而由于森林生态服务供给主体明确, 消费主体不明确[2], 被消费的生态服务难以量化[3], 不可避免的造成公共资源的“搭便车”行为。另外由于落后地区生存发展的需求, 地方营林部门可能与政府“合谋”通过牺牲资源环境质量来换取经济利益最大化[4]。由此可见, 跨区域森林生态补偿不仅是技术难题, 更是复杂利益相关者的不同利益诉求和行为导向冲突作用下的现实困境[5]。鉴于此, 经典博弈理论被国内外学者广泛用于揭示多边主体的利益与行动冲突问题。胡振通等[6]应用完全信息静态博弈探讨政府与牧民之间草原生态补偿的监管问题。曲富国和孙宇飞[7]通过构建基于成本收益的博弈模型, 研究上下游地区政府间生态补偿存在的问题、原因及对应的策略。张彰[8]从博弈的视角提出, 生态功能区财政补偿资金应该由中央政府和高发展程度地区政府共同承担。但是以上研究都是建立在个体理性的假设前提下, 难以解释现实中生态补偿信息的不完备性、个体到群体作用机制复杂性等问题。而演化博弈将有限理性纳入到经典博弈中, 假定参与者不拥有博弈形式或博弈规则的完全知识, 研究参与者在既定博弈形式下对均衡策略的学习[9]。Sheng等[10]构建了发展中国家和发达国家之间的森林生态补偿的演化博弈模型, 分析不同情形下REDD+项目的实施者和受益者的演化稳定策略。Li等[11]基于非对称演化博弈模型, 研究中国扬子江流域跨界利益主体的演化相位图和进化稳定策略, 结果表明, 地方政府引导, 企业和公众的共同参与才能避免非合作的“囚徒困境”。胡振华等[12]以漓江流域为例, 利用演化博弈模型探究跨界流域上下游政府之间的利益均衡及生态补偿机制, 并指出只有在引入中央政府的约束机制下才能实现最优稳定均衡策略。而李昌峰等[13]也同样基于演化博弈理论研究流域政府之间的生态补偿问题, 得出中央政府约束机制是实现稳定均衡的条件。宗鑫等[14]将第三方NGO组织的约束机制纳入到演化博弈模型中, 研究黄河流域上游青藏高原区的生态补偿问题。
从已有研究来看, 我国跨区域森林生态补偿的长效机制和制度机制尚未形成突破, 在跨界流域生态补偿问题上治理路径也不够清晰。同时, 研究方法大多以完全理性为前提分析地方政府间及政府与企业间的静态博弈关系。森林生态环境问题具有长期性、动态性和信息不完备性等特征, 因此演化博弈模型将博弈理论分析与动态演化分析相结合, 不要求参与人是完全理性且拥有完全信息, 有利于从学习和变异过程中寻求动态均衡, 然而一些研究构建的演化博弈模型参数设计不足难以反应主体决策行为的演化特征。为拓展研究范围, 本文在探讨森林生态补偿利益主体间逻辑关系的基础上, 根据演化博弈的基本原理, 以有限理性的主体功能区内保护地区政府和受益地区政府为决策主体, 对比引入中央政府“约束-激励”机制前、后的演化稳定均衡策略, 以此揭示我国跨区域森林生态补偿中多边主体决策行为的演化特征, 为完善森林生态补偿提供理论参考。
1 森林生态补偿利益主体间的逻辑关联由于区域资源禀赋的差异, 主体功能区范围内, 一些地区承担着保护森林生态环境的责任, 一些地区承担经济发展的责任。因此通过在森林生态系统服务供给和需求间建立反馈级联, 来讨论利益相关者之间的逻辑关系, 如图 1所示:

|
| 图 1 森林生态系统服务供求及补偿利益相关主体的逻辑关联图 Fig. 1 The logic relation diagram of forest ecological compensation stakeholders |
第一, 森林生态系统服务是人类社会资本与自然生态系统结构、过程和功能共同作用的产物[15]。根据千年生态系统评估(MA)将森林生态系统服务分为供给服务、调节服务、支持服务和文化服务, 其中供给服务中木材和林副产品可以通过市场交易实现价值, 而森林生态系统的调节服务、支持服务和文化服务中大部分功能属于纯公共物品或准公共物品[16], 如森林涵养水源、保持水土、气候调节和维持生物多样性等, 这些功能由于不存在价格信号, 因而无法通过市场机制实现资源配置, 森林生态服务提供者也没有获取相应的市场收益。但是这些外溢的生态服务能够满足受益地区对物质、健康和安全等需求, 人类通过对森林生态服务的消费和占用提高自身福祉, 最终实现森林生态系统的生态价值。
第二, 生态补偿有多种方式:包括区域内补偿和区域外补偿(跨区域补偿)[17], 常用的补偿段包括政府补偿和市场化补偿, 现有的森林生态补偿主要以政府间的转移支付为主, 只有部分森林旅游、碳汇实现市场化补偿。根据主体功能区的划分情况, 将限制开发区和禁止开发区内自然资源条件较好的生态功能区定义为保护地区, 而优化开发区和重点开发区主要以经济建设为主, 故定义为受益地区。此外有研究表明, 地方政府是公众的中性代理人[18], 能够更有效率地按照居民的偏好和辖区条件供给公共物品[19], 因此地方政府与区域内的企业、个人具有利益一致性, 故运用地方政府代表主体功能区的企业和个人。本文的森林生态服务利益群体包括保护地区政府、受益地区政府和中央政府, 由于生态环境保护带来的机会成本与生态服务的外溢性, 避免人类社会的“搭便车”行为, 一方面需要中央政府给予保护地区政府以转移支付形式的垂直生态补偿, 另一方面, 受益地区政府需要自觉或在中央政府约束和激励的作用下补偿保护地区政府, 实现森林生态环境的协同共治。
2 跨区域森林生态补偿演化博弈模型构建 2.1 问题描述与研究假设森林生态环境治理不仅是保护地区政府的一己之责, 需要跨区域政府间的联动协作, 应确定相关利益主体的责权利分担, 即明确相关主体的责任、权利, 平衡相关主体的利益, 从而促进森林生态环境的可持续发展。因此, 基于“谁提供服务谁获补偿, 谁受益谁补偿”的原则, 主要考虑保护地区政府和受益地区政府两类群体。为进一步明晰相关问题, 本文结合现实情况提出如下假设:
假设1:保护地区政府和受益地区政府均为有限理性行为主体, 博弈方始终追求自身利益最大化。
假设2:博弈方分别来自于不同的总体, 博弈成员间随机配对和相互学习进行动态重复博弈, 其策略选择的过程可以用博弈主体的复制动态方程来模拟。
假设3:反复在保护地区政府和受益地区政府两个群体中分别随机抽取一个参与者进行博弈, 保护地区政府的策略空间为{保护, 不保护};受益地区政府的策略空间为{补偿, 不补偿}。“保护-补偿”策略是社会所期盼的最优策略。
2.2 博弈模型设计构建跨区域森林生态补偿演化博弈模型支付矩阵符号假定为:L表示保护地区选择保护森林策略时全区获得的生态收益;C表示保护地区为保护森林生态环境而损失的机会成本;R1表示保护地区保护森林生态环境时, 受益地区获得的收益;R2表示保护地区不保护森林生态环境时, 受益地区获得的收益;P表示受益地区支付的生态补偿费用。保护地区和受益地区的博弈支付矩阵如表 1所示。
| 保护地区政府 Protecting governments |
受益地区政府Benefited governments | |
| 补偿Compensating | 不补偿Non-compensating | |
| 保护Protecting | (L+P-C, R1-P) | (L-C, R1) |
| 不保护Non-protecting | (P+C-L, R2-P) | (C-L, R2) |
假设保护地区政府采取“保护”策略的概率为x, 则采取“不保护”策略的概率为1-x, 当x=1时, 保护地区政府群体全部采取保护策略, 当x=0时, 保护地区政府群体全部采取不保护策略;受益地区政府采取“补偿”策略的概率为y, 采取“不补偿”策略的概率为1-y, 当y=1时, 受益地区政府群体全部采取补偿策略, y=0时, 受益地区政府群体全部采取不补偿策略。x、y均关于时间t的函数。
首先构建保护地区政府群体的复制动态方程, 保护地区政府选择“保护”、“不保护”策略的期望收益与平均期望收益分别为μ1、μ2、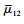
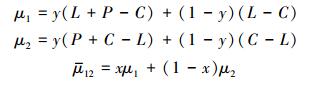
|
因此保护地区政府采取“保护”策略的复制者动态方程为:
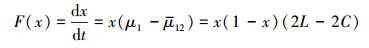
|
同理构建受益地区政府群体的复制动态方程。受益地区政府选择“补偿”、“不补偿”策略的期望收益与平均期望收益分别为μ3、μ4、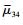
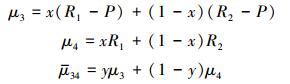
|
因此受益地区政府群体“补偿”策略的复制动态方程为:
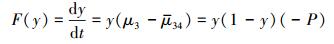
|
由保护地区政府和受益地区政府群体的复制动态方程构成跨区域生态补偿利益关系主体的复制动态系统:
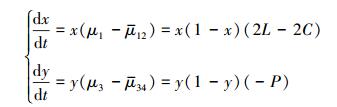
|
该系统的局部均衡点构成演化博弈均衡策略, 保护地区政府和受益地区政府都是决策者, 相对于个体决策, 保护地区政府(受益地区政府)群体的保护(补偿)策略随着时间发生变化, 通过不断的改变他们的策略而获得最大的目标收益, 当复制者动态方程组F(x)=0, F(y)=0时, 保护地区政府和受益地区政府达到均衡, 得到4个局部均衡点:A(0, 0)、B(1, 0)、C(0, 1)、D(1, 1)。
为确定生态补偿利益群体关系演变的最终结果, 需要对该系统各个局部均衡点进行稳定性分析, 根据Friedman提出用雅克比(Jacobi)矩阵进行局部均衡点的稳定性分析可以检验该博弈系统的稳定状态, 对于该博弈的动态系统, 其雅克比矩阵以及对应的行列式和迹表达式为:
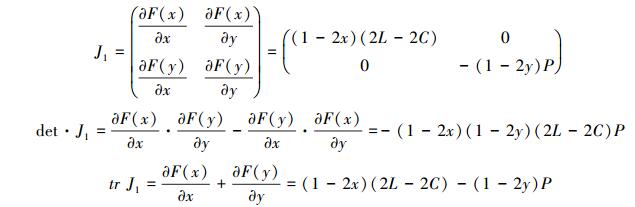
|
根据雅克比矩阵的局部分析法, 对4个均衡点进行稳定性分析, 如表 2所示。
| 局部均衡点 Local equilibrium point |
Det(J1) | Tr(J1) |
| (0, 0) | -(2L-2C)·P | 2L-2C-P |
| (1, 0) | (2L-2C) ·P | -2L+2C-P |
| (0, 1) | (2L-2C) ·P | 2L-2C+P |
| (1, 1) | -(2L-2C) ·P | -(2L-2C-P) |
| Det:行列式Determinant; Tr:迹Trace; J:雅可比式Jacobian | ||
从表 2可以看出, 动态复制系统均衡点的行列式值和迹的正负性与受益地区政府的收益无关, 仅与保护地区政府保护森林生态环境的收益和机会成本相关, 因此, 保护地区政府的决策对系统的均衡点起关键作用。
2.3.2 演化稳定均衡的参数讨论根据Fridman的思想, 若策略(x, y)为稳定的均衡策略, 则相应的有Det(J1)>0, Tr(J1) < 0。由以上分析可知, 系统稳定的均衡点取决于保护地区政府的收益和机会成本的大小, 故分为以下两种情形:
情形1:如表 3所示, 当L>C时, 2L-2C>0, 根据雅克比矩阵的均衡条件, 可知B(1, 0)点是演化博弈的均衡点, 其余各点A(0, 0)、C(0, 1)和D(1, 1)都不符合均衡的条件。由此可知当保护地区政府群体保护森林环境的收益大于机会成本时, 无论受益地区采取何种策略, 最终利益相关群体的稳定均衡点为(保护, 不补偿)。也表明了保护地区从环境中获得的收益足够高时, 即使没有中央政府的管制、受益地区政府补偿, 仍然可以实现保护森林资源的目的。
| 局部均衡点 Local equilibrium point |
2L-2C>0 | 2L-2C < 0 | |||||
| Det(J1) | Tr(J1) | 稳定性 | Det(J1) | Tr(J1) | 稳定性 | ||
| (0, 0) | - | +/- | 不稳定 | + | - | ESS | |
| (1, 0) | + | - | ESS | - | +/- | 不稳定 | |
| (0, 1) | + | + | 不稳定 | - | +/- | 不稳定 | |
| (1, 1) | - | +/- | 不稳定 | + | + | 不稳定 | |
| ESS:演化稳定策略evolutionarily stable strategy | |||||||
情形2:当L < C时, 2L-2C < 0, 同理根据雅克比矩阵的均衡条件, A(0, 0)点为演化稳定的均衡点。即保护地区保护森林资源的收益小于机会成本时, 无论保护地区与受益地区最初采取什么策略, 最终的稳定均衡点为(不保护, 不补偿)。说明社会期盼的最优稳定均衡策略(保护, 补偿), 无法通过保护地区政府与受益地区政府的自身演化实现, 表明若想实现最优策略, 需要中央政府的约束、管制等适当干预。
3 引入“约束-激励”机制后的森林生态补偿演化博弈模型从以上研究中可以看出, 当保护地区政府保护森林生态环境的收益大于机会成本时, 即使受益地区政府不支付补偿, 保护地区也有足够的激励保护森林资源, 但当保护森林的机会成本大于收益时, 保护地区政府和受益地区政府就会陷入“囚徒困境”, 即“不保护, 不补偿”策略为演化均衡策略, 因此为避免双方陷入非合作博弈, 必须引入上级政府“约束-激励”机制进行限制。
在以往的研究中, 很多作者只关注中央政府的约束机制[20], 而对激励机制鲜有说明。本文假设当保护地区政府对森林资源进行保护时, 而受益地区进行补偿时, 中央政府对两者进行一定的奖励, 用B表示, 当保护地区政府与受益地区政府有一方采取“不保护/不补偿”策略时, 中央政府对违规行为进行经济制裁(罚款、税金或碳排放收费等形式), 用F(F>P)表示。此时, 保护地区政府与受益地区政府的博弈支付矩阵如表 4。
| 保护地区政府 Protecting governments |
受益地区政府Benefited governments | |
| 补偿Compensating | 不补偿Non-compensating | |
| 保护Protecting | (L+P-C+A, R1-P+B) | (L-C+B, R1-F) |
| 不保护Non-protecting | (P+C-L-F, R2-P+B) | (C-L, R2) |
在中央政府的“约束-激励”机制下, 保护地区采取保护策略的复制者动态方程为:
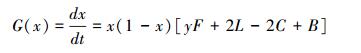
|
令G(x)=0, 可知x*=0和x*=1是复制动态方程的两个稳定状态点。
(1) 如果y=y*=(2C-2L-B)/F, 0≤(2C-2L-B)/F≤1成立时, 那么G(x)始终为0, 这意味着当受益地区政府以y=y*的水平选择“补偿”策略时, 保护地区政府选择两种策略的收益并没有区别。
(2) 当y>y*=(2C-2L-B)/F时, x*=0, x*=1是x可能的两个稳定状态, 对方程G(x)求导, 得G′(1) < 1, 所以x=1是演化稳定策略, 即受益地区政府以高于(2C-2L-B)/F水平选择“补偿”策略时, 保护地区政府从“不保护”策略逐渐趋向于“保护”策略, 即“保护”策略是演化稳定均衡策略, 从上式中可以看出当F越大时, y>y*的条件越容易满足, 也即当中央政府制定的罚款越高时, 越容易实现最优稳定均衡策略。
(3) 当y < y*=(2C-2L-B)/F时, x*=0, x*=1是x可能的两个稳定状态, 对方程G(x)求导, 得G′(0) < 1, 所以x=0是演化稳定策略, 即受益地区政府以低于(2C-2L-B)/F水平选择“补偿”策略时, 保护地区政府从“保护”策略逐渐趋向于“不保护”策略, 即“不保护”策略是演化稳定均衡策略。
3.1.2 受益地区政府的演化稳定策略分析受益地区政府采取“补偿”策略的复制者动态方程为:
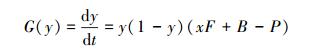
|
令G(y)=0, 根据复制动态方程, 得出y*=0, y*=1两个可能的稳定状态点。
(1) 当x=x*=(P-B)/F时, 总有G(y)=0, 即对于所有的y水平都有稳定状态, 在这种情况下, 当保护地区政府以(P-B)/F水平选择保护策略时, 受益地区政府选择两种策略收益没有区别。
(2) 当x>x*=(P-B)/F时, y*=0, y*=1是两个可能的稳定状态点, 对G(y)求导, 得G′(1) < 0, 所以y=1是演化稳定策略。即当保护地区政府以高于(P-B)/F的水平选择保护策略时, 受益地区政府逐渐由“不补偿”向“补偿”策略转移, 即“补偿”策略为演化稳定均衡点。
(3) 当x < x*=(P-B)/F时, y*=0, y*=1是两个可能的稳定状态点, 对G(y)求导, 得G′(0) < 0, 所以y=0是演化稳定策略。即当保护地区政府以低于(P-B)/F的水平选择保护策略时, 受益地区政府逐渐由“补偿”向“不补偿”策略转移, 即“不补偿”策略为演化稳定均衡点。
3.2 关联主体演化稳定策略参数讨论基于以上分析, 可得保护地区政府与受益地区政府跨区域生态补偿的复制动态系统:
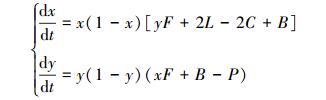
|
在中央政府“约束-激励”机制下, 森林生态补偿演化博弈模型的均衡点有5个, 即A(0, 0)、B(0, 1)、C(1, 0)、D(1, 1)、E(x*, y*)。为确定相关主体在生态补偿过程中演化稳定的均衡条件, 依据G(x)与G(y)构建博弈复制动态系统。根据Friedman的思想, 得到雅克比矩阵以及对应的行列式和迹。
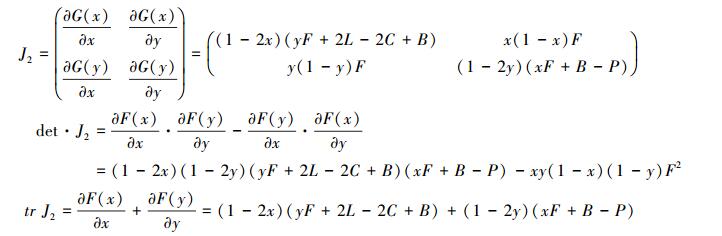
|
根据局部均衡点分析可知, 该演化博弈的稳定性与受益地区政府的收益R1、R2无关, 需要根据保护地区政府的收益参数值以及中央政府的“约束-激励”参数大小判断演化博弈的均衡点, 由此可知保护地区政府与中央政府的决策是该演化博弈均衡点的关键。根据上一节的研究可知, 当C < L时, 2C-2L < 0, 即保护地区政府保护森林资源的收益大于机会成本时, 即使受益地区政府不补偿, 仍能够实现保护森林生态环境的最终目标, 演化稳定策略是(保护, 不补偿), 因此这里只需要考虑2C-2L>0的情况。根据表 5可知, 若假设D(1, 1)为唯一稳定策略, 其稳定性的参数讨论可以分为以下四种情况:

|
| 局部均衡点Local equilibrium point | Det(J2) | Tr(J2) |
| (0, 0) | (2L-2C+B)·(B-P) | 2L-2C+2B-P |
| (1, 0) | -(2L-2C+B)·(F+B-P) | 2C-2L+F-P |
| (0, 1) | -(2L-2C+F+B)·(B-P) | 2L-2C+F+P |
| (1, 1) | (2L-2C+B+F)·(F+B-P) | -(2F+2B+2L-2C-P) |
| (x*, y*) | [(B-P)(2C-2L-B)(F-P-B)(F-2C+2L+B)]/F2 | 0 |
| *表示演化稳定策略点 | ||
由局部稳定性分析结果可知, 在前三种情况下, D(1, 1)为唯一稳定策略, 在第四种情况下A(0, 0)和D(1, 1)同时为该博弈的均衡点(见表 6和图 2)。因此根据复制动态相位图显示只有满足情形1、情形2和情形3时, 跨区域森林生态补偿的演化博弈才存在唯一的稳定策略(保护, 补偿), 可得出在此条件下, 中央政府“约束-激励”机制的参数(惩罚金额F, 奖励金额B)的范围为: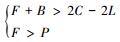
| 均衡点 | 情形1 Case1 | 情形2 Case2 | 情形3 Case3 | 情形4 Case4 | |||||||||||
| Det(J2) | Tr(J2) | 稳定性 | Det(J2) | Tr(J2) | 稳定性 | Det(J2) | Tr(J2) | 稳定性 | Det(J2) | Tr(J2) | 稳定性 | ||||
| (0, 0) | + | + | 不稳定 | - | +/- | 不稳定 | - | + | 不稳定 | + | - | ESS | |||
| (1, 0) | - | + | 不稳定 | - | + | 不稳定 | - | + | 不稳定 | + | + | 不稳定 | |||
| (0, 1) | - | +/- | 不稳定 | - | + | 不稳定 | + | +/- | 不稳定 | + | +/- | 不稳定 | |||
| (1, 1) | + | - | ESS | - | +/- | ESS | + | - | ESS | + | - | ESS | |||
| (x*, y*) | +/- | 0 | 鞍点 | + | - | 鞍点 | +/- | 0 | 鞍点 | +/- | 0 | 鞍点 | |||

|
| 图 2 主体功能区利益群体的复制动态相位图 Fig. 2 Repetitive dynamic phase diagram of interest group of main function area |
即中央政府惩罚和奖励的金额之和要大于保护地区保护森林资源的损失, 同时惩罚金额要大于受益地区的补偿金额。
4 结论与讨论生态补偿机制是保护森林生态环境、均衡各方利益的有效手段, 本文在讨论跨区域森林生态补偿行动中主体功能区利益主体间逻辑关联的基础上, 构建保护地区政府和受益地区政府的演化博弈模型, 分析了两方主体反复博弈、学习和策略调整的过程, 最后通过引入中央政府的“约束-激励”机制, 能够实现最优的演化稳定均衡策略, 主要结论如下:(1)演化稳定均衡策略与保护地区政府保护森林资源的机会成本与收益密切相关, 当机会成本大于生态收益时, 演化稳定策略均衡点为(不保护, 不补偿)。当机会成本小于生态收益时, 演化稳定均衡点为(保护, 不补偿), 即保护地区政府生态收益较高时, 即使没有中央政府的管制和受益地区政府补偿, 仍有激励保护森林生态环境。(2)演化博弈模型中, 保护地区政府与受益地区政府关联演化固然重要, 但是在演化过程中给予对方一定的信息和外部条件, 参与人通过改变自己的支付函数, 博弈均衡就能得到改变。如保护地区政府以高于(P-B)/F的水平选择保护策略时, 受益地区政府逐渐由“不补偿”向“补偿”策略转移。而受益地区政府以高于(2C-2L-B)/F水平选择“补偿”策略时, 保护地区政府从“不保护”策略逐渐趋向于“保护”策略。(3)引入中央政府的“约束-激励”机制后, 跨区域森林生态补偿最优的演化稳定均衡点取决于中央政府惩罚和奖励参数的范围, 当中央政府惩罚和奖励金额之和大于保护地区保护森林资源总损失的2倍、并且惩罚金额要大于受益地区的补偿金额时, 有唯一演化稳定均衡点(保护, 补偿)。
主体功能区划形成了新的“地理空间+职能空间+政策空间”复合体, 各区域之间的内在结构和外部政策存在差异, 造成不同区域间利益不均衡[21], 使森林生态保护成本与区域生态利益错配问题严重, 从而引发对新的生态补偿机制的迫切需求。因此在分析主体功能区利益群体关系的基础上, 考虑跨区域地方政府间的博弈决策行为就显得非常必要。相对于经典博弈理论, 演化博弈以有限理性为前提, 运用策略互动的思想, 引入突变机制将传统的纳什均衡精炼为演化稳定均衡, 同时引入选择机制构建复制动态模型, 更适用于分析跨区域生态补偿机制构建过程中地方政府行为范式的演化, 以及多主体互相作用的关系。
跨区域森林生态补偿的实质是一个利益博弈再调整的的过程, 最终的目的是实现森林生态环境的可持续发展[22], 但是在没有中央政府“约束-激励”机制下很难实现, 主要是因为:一方面由于森林生态服务具有显著的正外部性, 价值难以量化, 外溢的服务不能有效的转换为经济价值, 导致消费主体不明确;另一方面, 财政分权体制下各地政府进行着激烈的经济竞争和赶超, 使理性的地方政府更倾向于投入基础建设领域[23], 此外森林生态保护成本投入高、回报周期长与地方官员追求短期政绩间存在矛盾和冲突, 导致跨区域政府之间合作困难。因此立足上述分析, 走出跨区域合作困境, 提出以下几点建议:(1)突出中央政府在跨区域合作中的主导作用。中央政府在纵向补偿的基础上构建横向生态转移支付制度, 同时建立内部约束激励机制, 改良单一GDP政绩考核标准, 加强跨区域生态补偿的制度供给和政策工具支撑。(2)结合主体功能区的自然资源特点, 限制和禁止开发区应该注重发展生态产业经济, 鼓励林区政府发展森林旅游、森林养生、林下种植、林下养殖等产业, 遵循比较优势发展战略, 使保护森林生态受益大于成本。另外要倡导优化和重点开发区收入水平较高居民购买生态产品, 选择森林生态游, 营造共同利益空间。(3)明确森林生态产品和服务的产权, 利用生态资源资产化、生态资产资本化的过程, 实现森林资源从服务流向价值流转换。跨区域生态补偿的难点在于森林生态服务的价格难以确定, 因此利用一定的技术条件实现以市场交易价值反应森林生态产品和服务, 这样一种资本化的过程使跨区域生态补偿得以实现。
| [1] |
Costanza R, Groot R D, Sutton P, van der Ploeg S, Anderson S J, Kubiszewski I, Farber S, Turner R K. Changes in the global value of ecosystem services. Global Environmental Change, 2014, 26: 152-158. DOI:10.1016/j.gloenvcha.2014.04.002 |
| [2] |
伏润民, 缪小林. 中国生态功能区财政转移支付制度体系重构——基于拓展的能值模型衡量的生态外溢价值. 经济研究, 2015, 50(3): 47-61. |
| [3] |
Lu H F, Campbell E T, Campbell D E, Wang C W, Ren H. Dynamics of ecosystem services provided by subtropical forests in Southeast China during succession as measured by donor and receiver value. Ecosystem Services, 2017, 23: 248-258. DOI:10.1016/j.ecoser.2016.11.012 |
| [4] |
姜珂, 游达明. 基于央地分权视角的环境规制策略演化博弈分析. 中国人口·资源与环境, 2016, 26(9): 139-148. DOI:10.3969/j.issn.1002-2104.2016.09.017 |
| [5] |
许玲燕, 杜建国, 汪文丽. 农村水环境治理行动的演化博弈分析. 中国人口·资源与环境, 2017, 27(5): 17-26. |
| [6] |
胡振通, 孔德帅, 靳乐山. 草原生态补偿:弱监管下的博弈分析. 农业经济问题, 2016, 37(1): 95-102. |
| [7] |
曲富国, 孙宇飞. 基于政府间博弈的流域生态补偿机制研究. 中国人口·资源与环境, 2014, 24(11): 83-88. DOI:10.3969/j.issn.1002-2104.2014.11.011 |
| [8] |
张彰. 生态功能区财政补偿资金来源负担归属研究——基于微观经济学的博弈分析. 中央财经大学学报, 2016(11): 19-27. |
| [9] |
黄凯南. 主观博弈论与制度内生演化. 经济研究, 2010, 45(4): 134-146. |
| [10] |
Sheng J C, Wu Y, Zhang M Y, Miao Z. An evolutionary modeling approach for designing a contractual REDD+ payment scheme. Ecological Indicators, 2017, 79: 276-285. DOI:10.1016/j.ecolind.2017.04.010 |
| [11] |
Li F, Pan B, Wu Y Z, Shan L P. Application of game model for stakeholder management in construction of ecological corridors: A case study on Yangtze River Basin in China. Habitat International, 2017, 63: 113-121. DOI:10.1016/j.habitatint.2017.03.011 |
| [12] |
胡振华, 刘景月, 钟美瑞, 洪开荣. 基于演化博弈的跨界流域生态补偿利益均衡分析——以漓江流域为例. 经济地理, 2016, 36(6): 42-49. |
| [13] |
李昌峰, 张娈英, 赵广川, 莫李娟. 基于演化博弈理论的流域生态补偿研究——以太湖流域为例. 中国人口资源与环境, 2014, 24(1): 171-176. |
| [14] |
宗鑫, 赵龙, 王光耀, 韦惠兰. 生态补偿的复制动态及其进化稳定策略研究——以黄河流域上游青藏高原区为分析背景. 干旱区资源与环境, 2016, 30(9): 32-37. |
| [15] |
Jones L, Norton L, Austin Z, Browne A L, Donovan D, Emmett B A, Grabowski Z J, Howard D C, Jones J P G, Kenter J O, Manley W, Morris C, Robinson D A, Short C, Siriwardena G M, Stevens C J, Storkey J, Waters R D, Willis G F. Stocks and flows of natural and human-derived capital in ecosystem services. Land Use Policy, 2016, 52: 151-162. DOI:10.1016/j.landusepol.2015.12.014 |
| [16] |
Bösch M, Elsasser P, Franz K, Lorenz M, Moning C, Olschewski R, Rödl A, Schneider H, Schröppel B, Weller P. Forest ecosystem services in rural areas of Germany: Insights from the national TEEB study. Ecosystem Services, 2018, 31: 77-83. DOI:10.1016/j.ecoser.2018.03.014 |
| [17] |
温薇, 田国双. 生态文明时代的跨区域生态补偿协调机制研究. 经济问题, 2017(5): 84-88. |
| [18] |
尹振东, 汤玉刚. 专项转移支付与地方财政支出行为——以农村义务教育补助为例. 经济研究, 2016, 51(4): 47-59. |
| [19] |
李涛, 刘思玥. 分权体制下辖区竞争、策略性财政政策对雾霾污染治理的影响. 中国人口·资源与环境, 2018, 28(6): 120-129. |
| [20] |
潘峰, 西宝, 王琳. 地方政府间环境规制策略的演化博弈分析. 中国人口·资源与环境, 2014, 24(6): 97-102. DOI:10.3969/j.issn.1002-2104.2014.06.015 |
| [21] |
廖晓慧, 李松森. 完善主体功能区生态补偿财政转移支付制度研究. 经济纵横, 2016(1): 108-113. |
| [22] |
彭皓玥. 公众权益与跨区域生态规制策略研究——相邻地方政府间的演化博弈行为分析. 科技进步与对策, 2016, 33(7): 42-47. |
| [23] |
郑洁, 付才辉, 张彩虹. 财政分权与环境污染——基于新结构经济学视角. 财政研究, 2018(3): 57-70. |