 2019, Vol. 39
2019, Vol. 39文章信息
- 陈黔, 李晓松, 修晓敏, 杨广斌
- CHEN Qian, LI Xiaosong, XIU Xiaomin, YANG Guangbin
- 基于Google Earth Engine与机器学习的大尺度30m分辨率沙地灌木覆盖度估算
- Large scale shrub coverage mapping of sandy land at 30m resolution based on Google Earth Engine and machine learning
- 生态学报. 2019, 39(11): 4056-4069
- Acta Ecologica Sinica. 2019, 39(11): 4056-4069
- http://dx.doi.org/10.5846/stxb201811292601
-
文章历史
- 收稿日期: 2018-11-29
- 修订日期: 2019-04-26

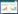




2. 中国科学院 遥感与数字地球研究所 数字地球重点实验室, 北京 100094
2. Key Laboratory of Digital Earth Science, Institute of Remote Sensing and Digital Earth, Chinese Academy of Sciences, Beijing 100094, China
与乔木林相比, 灌木林在整个生态系统中所占的比重较小, 但由于其对水分、养分条件要求不高, 一直以来在干旱、半干旱区有着大量的分布[1]。因此, 灌木对于干旱生态系统的稳定与平衡起着十分重要的作用[2]。准确掌握沙地灌木分布及动态具有重要的生态学意义。传统植被分布调查主要以地面观测为主, 该方法具有一定的局限性, 例如在人力、物力上的花费都比较大, 样地的外推也面临着较大的不确定性[3]。随着遥感对地观测技术的不断发展, 使得大区域、大尺度的植被监测成为了可能, 而植被类型分类与覆盖度估算一直是植被遥感监测领域的热点, 已在全球不同尺度、不同地区得到了广泛的应用[4-8]。目前, 绝大部分植被类型遥感分类以像元或若干像元的组合(对象)为基本单元, 将其划归为某一指定植被类型[9-10], 并未考虑像元中不同植被类型混合存在的情况, 而这一问题对于中低分辨率遥感数据来说相当普遍, 特别是在地表空间异质性较强的区域[11-12]。意识到这一问题, 估算每一像元特定植被类型覆盖度的研究得到了开展, 其中最为成熟、应用最为广泛的是全球MODIS FVC树木覆盖度产品[13], 并且Sexton等人[14]已通过尺度转换方法生产了全球30m空间分辨率树木覆盖度产品。值得指出的是, FVC产品中树木覆盖度主要反映的是高于5m的树木的覆盖度, 并将灌木与草本等定义为其他植被覆盖度, 显然无法满足灌木信息提取的需求, 另外其精度在以稀疏森林为主的干旱地区也存在较大疑问[15]。针对干旱地区的特殊情况, 木本植被覆盖度(包括乔木/灌木)的估算研究得到了开展[16], 基于时间序列MODIS数据提取的季节参数估算了整个萨赫勒地区的木本覆盖度, Higginbottom等[17]基于Landsat数据利用机器学习的方法估算了南非较小区域的木本覆盖度。与FVC产品不同, 这些研究将乔木与灌木信息混合在了一起, 也无法满足灌木覆盖度提取的需求。因此, 发展一个大尺度、中高分辨率、适用于干旱地区沙地、可与高大乔木与草本区分的灌木覆盖度遥感估算方法具有重要的意义。
植被覆盖度估算最为常用的就是植被指数法, 一般而言植被指数与植被覆盖度之间具有较高的相关性, 但单纯利用植被指数往往无法区分不同植被类型, 并且受到荒漠地区植被稀疏及地表异质性较强的影响, 植被指数对于以根茎生长为主的灌木探测能力不足[11]。混合像元分解法也得到了广泛应用, 该方法的优势是不需要采集大量地面样本, 然而合理的端元选取对估算精度影响较大, 导致该方法的估算结果可能存在较大误差[18-19]。与上述方法相比, 机器学习方法运算速度更快、稳定性更高且不容易产生过拟合, 通过构建样本数据集, 结合地形、气候、植被指数、光谱信息等众多变量, 往往能构建出更为稳定的估算模型[14, 16, 20]。考虑到大区域、多时相中高分辨率光学遥感数据的可用性及机器学习算法的计算需求, Google Earth Engine(GEE)遥感分析云平台已成为开展相应研究的最佳工具之一。GEE提供了校正后的全球Landsat系列数据, 并提供了机器学习算法接口[21]。研究人员已经利用GEE开展了国家尺度植被动态监测[22]、洲际尺度耕地制图[23-24]、全球地表温度估算[25]等等。然而, 尚没有针对沙地灌木覆盖度估算的相关研究。
为此, 本研究提出了充分利用GEE遥感云平台, 通过Collect Earth工具构建地面灌木覆盖度样本库, 以Landsat-8影像及其他辅助数据为变量, 通过机器学习方法开展大尺度时间序列灌木覆盖度估算的技术体系, 并以中国北方毛乌素沙地为示范区开展了应用, 并对其应用效果进行了评价, 以期为大尺度沙地灌木覆盖度估算提供参考。
1 研究区概况毛乌素沙地位于鄂尔多斯高原东南部和陕北黄土高原以北的洼地, 覆盖内蒙古自治区的鄂尔多斯南部、陕西省榆林市的北部风沙区和宁夏回族自治区盐池县东北部小片区域[26], 如(图 1)所示。地理位置为37°27′30″—39°22′30″N, 107°20′—111°30′E, 地处中国东部季风的尾闾地区, 属典型大陆性半干旱气候, 年降水量在250—440mm之间, 面积约为4.22万km2, 在中国北方第二大沙地。毛乌素沙地流动沙地、半固定沙地分布较为广泛, 荒漠化进程迅速, 因此, 一直以来都是我国荒漠化治理的重点地区[27]。土壤在毛乌素沙地分布具有明显的地带性变化特征。在梁地、沙地地区, 土壤主要以栗钙土和棕钙土为主;在滩地中土壤主要呈草甸土—盐化草甸土—盐土过渡的形式;在河谷阶地中, 土壤由淡栗钙土过渡为盐化草甸土。整体来看, 毛乌素沙地土壤偏沙性, 其中栗钙土、棕钙土、灰钙土、风沙土所占面积较大, 养分含量低[28]。灌木植被是毛乌素沙地最具代表性, 同时也是分布最为广泛的植物群落。西鄂尔多斯荒漠地区大量分布超旱生灌木, 如低矮灌木狭叶锦鸡儿(Caragana stenophylla)、驼绒黎(Ceratoides latens)等, 中部及中东部干草原地区植被物种丰富多样, 并保有大量的原生灌木、半灌木植被, 这其中就包括油蒿(Artemisia ordosica)、白沙蒿(Artemisia sphaerocephala krasch)等蒿类植被以及杨柴(Hedysarum mongolicum)、柠条(Caragana korshinskii)等豆科植被[29]。随着三北防护林、京津冀风沙源等一系列生态恢复工程的推进, 据第五次全国荒漠化和沙化监测最新数据显示, 毛乌素沙地作为重点治理区域, 其植被覆盖情况, 尤其是作为优势植被的灌木覆盖情况发生了显著变化[30]。

|
| 图 1 毛乌素沙地地理位置、Landsat8影像NDVI最大合成、采样方分布 Fig. 1 The location of study area, Landsat-8 NDVI maximum value composite and coverage data collection site in Mu Us Sandy Land |
整体研究流程如(图 2)所示。首先, 数据准备工作包括两个部分, 其一是对多源遥感数据进行选取并进行预处理, 其二是通过两种采样法获取样本并构建样本数据集。其次, 提取样方对应多源数据, 包括光谱参数、植被指数、物候因子以及地形因子, 并对因子进行相关性分析。最后, 构建CART和SVM两种估算模型并进行精度验证, 最终产出灌木覆盖度产品。

|
| 图 2 沙地灌木覆盖度估算技术流程图 Fig. 2 Flowchart of methodology for shrub coverage estimation in sandy land |
(1) 卫星遥感数据
本研究基于GEE平台, 以陆地数据Landsat-5 TM以及陆地数据Landsat-8 OLI地表反射率影像为数据源, 利用GEE平台强大的运算能力对影像进行质量筛选、云掩膜及平均值计算, 获取毛乌素沙地2000—2017年(2012、2016除外)每年5—9月共80期地表反射率影像。在此基础上, 通过NDVI最大合成的方法生成了各年度生长季地表反射率影像。
除反射率外, 本研究计算了归一化植被指数(NDVI)、土壤调节植被指数(SAVI)、修正的土壤调节植被指数(MSAVI)、差值植被指数(DVI)[11, 32]4个植被指数作为输入参数, 以更好估算灌木覆盖度。
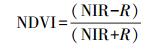
|
(1) |
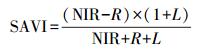
|
(2) |
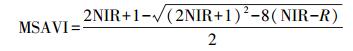
|
(3) |
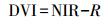
|
(4) |
式中, NIR为近红外波段反射率, R为红光波段反射率, L为降低土壤背景影响而设定的一个土壤调节参数, 该参数的值随植被的密度变化而变化, Huete[33]认为在大面积稀疏植被覆盖区域L取值为0.5时对消除土壤背景影响效果最佳。
(2) 地形数据获取与处理
地形数据调用GEE平台上的SRTM数字高程模型, 地形因子提取包括高程、坡度、坡向3个因子。
(3) 气候数据获取与处理
气候数据调用TerraClimate全球陆地表面月平均气候数据集[31]。气候因子提取包括降水、风速、帕尔默干旱指数、蒸散量4个因子作为输入参数。
输入变量汇总如表 1所示。四类因子共包含17个变量。
| 遥感数据集 Dataset |
产品ID Production ID |
获取时间 Data acquisition (time) |
遥感数据处理及信息提取 Data processing and information extraction |
| Landsat 5地表反射率1级产品 USGS Landsat 5 Surface Reflectance Tier 1 |
LANDSAT/LT05/C01/T1_SR | 2000—2011年每年6—9月 | 影像合成、裁剪、提取B1—B5以及B7波段、计算并提取植被指数 |
| Landsat 8地表反射率1级产品 USGS Landsat 8 Surface Reflectance Tier 1 |
LANDSAT/LC08/C01/T1_SR | 2013—2015年以及2017年每年6—9月 | 影像合成、裁剪、提取B2—B7波段、计算并提取植被指数 |
| SRTM 30m分辨率数字高程数据 SRTM Digital Elevation Data 30m |
USGS/SRTMGL1_003 | 2000年 | 提取高程、坡度、坡向 |
| 全球地表月平均气候和水平衡数据集 TerraClimate: Monthly Climate and Climatic Water Balance for Global Terrestrial Surfaces |
IDAHO_EPSCOR/TERRACLIMATE | 2000—2015年(2012年除外)以及2017年每年6—9月 | 提取月均降水、风速、帕尔默干旱指数以及蒸散量 |
样本数据集构建是本研究的关键步骤。在此, 我们运用了Collect Earth样本收集器, 这是一款由联合国粮农组织(FAO)开发的专业影像解译软件, 主要用于陆地数据的收集、管理及分析。该软件可以轻松地访问多个免费的高时空分辨率卫星影像存档, 利用这些数据的协同作用, 实现了一种全新的土地监测方法, 称为增强视觉解译法[34]。该方法可提升空间采样精度, 特别是在地表异质性较强的干旱、半干旱地区, 可解决植被稀疏所导致的采样困难问题。本研究对毛乌素沙地进行样本库构建, 样方以10km为间隔均匀分布在研究区内, 共415个大小为100m×100m的样方, 每个样方中等距分布有5×5, 共25个采样点, 每个采样点对应4%的地块, 采用等距取样法对每个采样方分别进行覆盖度提取, 如(图 3)所示, 通过这种方式实现覆盖度的量化。根据实际情况对样本进一步筛选, 将影像时效性较差、影像被云遮盖、影像分辨率较低的样方进行去除, 最终通过Collect Earth样本收集器获取376个有效样方。

|
| 图 3 基于Collect Earth样本收集器样点采集 Fig. 3 Illustration of sampling design and project properties |
2017年8月, 课题组依据标准一致的野外采样方案, 对毛乌素沙地开展灌木覆盖度调查, 共采集大小为30m×30m的样方24个。上述共400个样方数据为毛乌素沙地灌木覆盖度遥感估算打下了重要基础。
2.3 灌木覆盖度估算方法为提升数据的时间匹配度, 本研究运用GEE平台, 分别对Landsat-8及Landsat-5影像进行时间序列选取、云量筛选、生长季NDVI最大值合成以及镶嵌等处理, 对2010至2015年5年间(2012年除外)获取样方对应影像波段光谱值、植被指数、地形因子以及气候因子进行提取, 在此基础上分别构建分类回归树、支持向量机两种估算模型, 并对模型估算精度进行评价。
2.3.1 CART(Classification And Regression Tree)模型CART算法是Breiman[35]于1984年提出的一种基于决策树构建的算法, 实质上也是归纳学习算法中的一种。其主要原理是从已有的样本库中归纳出整体的某些特征规律, 生成树形分类结构从而用于除样本之外的事例分类。基本原理是通过训练数据集构建预测模型, 采用二分递归分割方法, 使得生成的非叶子节点都有两个分支。将多个分支预测模型进行拟合, 通过预测连续变量获得树形结构模型。该算法既可用于分类, 也可用于连续变量的预测, 可有效处理大区域、大样本量和髙维度的数据。
CART算法在树形结构生长过程中, 采用经济学中基尼(Gini)系数作为选择最优测试变量和分割阈值的准则, 其数学定义如下所示:
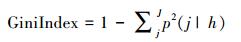
|
(5) |
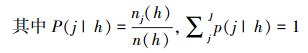
|
(6) |
式中, P(j|h)是从训练样本集中随机抽取的一个样本, 当某一测试变量值为h时属于第j类的概率, njh为训练样本中该测试变量值为h时属于第j类的样本个数, n(h)为训练样本中该测试变量值为h的样本个数, j为类别个数。
在本次研究中, 目标变量是灌木覆盖度, 测试变量是用于构建模型的各种辅助因子, 但如果仅按照上述方法生成的树形结构模型往往会出现“过拟合”的现象, 这是由于完整的树形结构模型对于样本数据集特征的描述“过于精确”其原因是受到了噪声影响, 失去了一般代表性从而无法对新数据进行下一步精确的分类, 针对该问题本研究采用K折交叉验证的方法进行叶子结点修剪, 在验证过程中引入一个“可调错误率”的概念, 即对某一树枝的全部叶子节点增加一个惩罚因子, 若该树枝仍然保持较低错误率, 则予以保留, 否则给予剪除。最终得出一颗适用于本研究且兼顾高复杂度与低错误率的最优二叉树[36]。
2.3.2 SVM(Support Vector Machine)模型支持向量机(SVM)通过引入核函数低维空间中线性不可分的问题映射到高维空间中, 其基本思想是通过使用位于类域边缘的支持向量, 在特征空间中的类之间构造分离超平面, 在高维空间中最大化不同类别之间的间隔寻求最佳超平面。
1997年, Vnpiak等人[37]基于回归函数构建了用于预测连续变量的支持向量回归(SVR)模型, 即给定训练样本集T={x(x1, y1), (x2, y2), ... (xN, yN)}, y1∈R, 目的是学习到一个f(x)使得其与y尽可能的接近, 其数学定义如下所示:
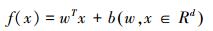
|
(7) |
式中,w和b为回归函数f(x)的斜率和偏移, d为维度输入空间。
选择合适的核函数对于SVR模型的关系构建非常重要, 前人的研究中较为常见的核函数有4种:1)线性核函数:K(xi, xj)=xi×xj;2)多项式核函数:K(xi, xj)= (xi×xj+1) d;3)Sigmoid核函数:K(xi, xj) =tanh[a (xi×xj)+b];4)径向基核函数(Radial Basis Function, RBF):K(xi, xj) =exp(-g‖xi-xj‖2)。在不同核函数的作用下, 数据在高维特征空间中的分布结构将不同, 从而直接决定了SVM与核方法的最终性能[38-39]。
本研究选择应用最广、普适性最强的RBF作为构建模型的核函数, 以基于样本点提取的各种辅助因子作为f(x)函数中的输入因子, 灌木覆盖度作为输出结果, 借助台湾大学林智仁(Lin Chih-Jen)教授开发的Libsvm工具箱[40]进行参数选择, 该工具箱具有参数调节相对较少以及提供很多默认参数的特点, 通过网格搜索法对RBF核函数中g参数和C(惩罚)参数进行选择, 主要步骤包括:(1)按照Libsvm软件包要求的格式准备数据集;(2)对数据集进行归一化处理;(3)选用RBF函数作为核函数并运用网格搜索算法;(4)采用交叉验证方法选择最佳参数C与g;(5)采用最优参数惩罚因子C和参数g构建支持向量机模型。
2.4 精度评价本研究样本数据库共包含400个样方, 每块样方均包含了乔木、灌木、草地及沙地四种覆盖类型。所有样方采集时间与影像信息提取时间基本保持一致, 最大限度的保证数据的时间匹配度。随机选取25%的样方对模型精度进行验证, 通过均方根误差(RMSE)、确定系数R2和估算精度(Estimation Accuracy, EA)[41]3个指标来评价不同模型估算灌木覆盖度的精度, 计算公式为:
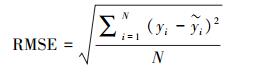
|
(8) |
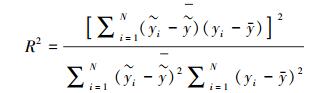
|
(9) |
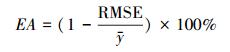
|
(10) |
式中,yi为实测灌木覆盖度, 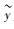
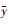
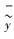
本研究采用Collect Earth样本收集器结合野外样地调查的方式构建样本数据集, 共获取400个样方。其中, 0—20%覆盖度的样方共205个, 占总样方数的51.3%;20%—40%覆盖度的样方共86个, 占总样方数的21.5%;40%—60%覆盖度的样方共63个, 占总样方数的15.8%;60%—80%覆盖度的样方共37个, 占总样方数的9.2%;80%—100%覆盖度的样方共9个, 占总样方数的2.3%。
从不同覆盖度样方空间分布情况来看, 如(图 4)所示, 覆盖度较高的区域主要集中在毛乌素沙地的东北缘, 有较多覆盖度大于60%的样方分布, 中东部地区主要分布覆盖度40%—60%的样方, 中部及中西部地区主要分布覆盖度低于20%的样方, 零星分布有覆盖度在20%—40%的样方。从整体上来看, 毛乌素沙地东部地区样方平均覆盖度要高于西部地区。

|
| 图 4 样本数据集灌木覆盖度地理位置分布图 Fig. 4 The distribution of different shrub coverage degree sampling points in Mu Us Sandy Land |
本研究涉及到了Landsat-5与Landsat-8两种数据, 尽管Landsat系列数据具有较好地延续性, 但比较GEE平台上大气校正后Landsat-5与Landsat-8数据一致性仍具有重要意义。因此, 我们选取一块未曾变化的典型区域(包括乔木、灌木、草地、沙地), 分别利用2011年和2013年最大NDVI合成影像进行相关性分析(共计11746个像元)。通过相关性分析得到Landsat-5和Landsat-8得到的各对应波段及植被指数决定系数分别为0.94, 0.92, 0.88和0.92, 如(图 5)所示, 均达到极显著水平(P<0.001), 表明两种传感器的反射率存在显著的相关[42]。其中近红外和短波红外波段的斜率趋近于1, 红光波段在4种波段中斜率相对较小但也达到了0.84。考虑到数据年份不一致, 上述结果说明两种传感器对应波段的反射率具有较高的一致性, 用于长时间序列样本光谱信息提取具有可行性。

|
| 图 5 Landsat-5与Landsat-8影像对应波段相关性分析 Fig. 5 Correlation analysis of corresponding channels between Landsat-5 and Landsat-8 |
不同类型变量与灌木覆盖度相关性分析结果如(图 6)所示。光谱参数各波段均在P=0.01水平上显著相关, 其中近红外波段相关性最强;各种植被指数均在P=0.01水平上显著相关, 其中NDVI、MSAVI、SAVI相关性一致, DVI相关性相对较低;物候因子中蒸散量以及降水在P=0.01水平上显著相关, 而风速与干旱指数相关性低;地形因子中坡度及坡向P=0.05水平上显著相关, 而高程相关性低。考虑到覆盖度与遥感影像之间关系复杂, 单一变量不能满足估算要求, 因此对四类参数因子进行综合选择, 分别选取各类因子中与覆盖度相关性较高的因子。针对植被指数, NDVI、SAVI、MSAVI 3个指数与覆盖度相关性一致, 并且三者之间自相关性强, 为避免波段信息重叠对模型产生影响, 因此只选其中一个(即NDVI)作为模型参数。同时, 相关研究表明DVI对低覆盖植被具有较强探测能力, 因此也将其选作模型参数[3]。最终选取近红外波段、NDVI、DVI、Precipitation、AET以及Slope作为构建模型的自变量。

|
| 图 6 覆盖度与17个变量的相关系数矩阵 Fig. 6 Correlation coefficient matrix between the coverage and 17 variables Elevation:高程;Slope:坡度;Aspect:坡向;PDSI:帕尔默干旱指数,Palmer Drought Severity Index;Precipitation:降水量;Wind speed:风速;AET:实际蒸散量,Actual Evapotranspiration;NDVI:归一化植被指数,Normalized Difference Vegetation Index;MSAVI:修正的土壤调节植被指数,Modified Soil-Adjusted Vegetation Index;SAVI:土壤调节植被指数,Soil-Adjusted Vegetation Index;DVI:差值植被指数,Difference Vegetation Index;Blue:蓝光波段;Green:绿光波段;Red:红光波段;NIR:近红外波段,Near Infrared;SWIR1:短波红外波段1,Shortwave Infrared 1;SWIR2:短波红外波段2,Shortwave Infrared 2;Coverage:覆盖度 |
利用CART对由上述的自变量和因变量组成的样本进行分析, (图 7)展示了CART树形结构的一部分, 为了防止过拟合, 对模型进行K-fold交叉验证(K=5), 树形结构为:首先以凹凸点NIR≤2309.00为切割点构造二叉树, 当NIR≤2309.00时, 通过Precipitation构造下一颗二叉树;当NIR>2309.00时, 通过NDVI构造下一颗二叉树, 树形结构不断生长, 最终通过剪枝得到一颗最优二叉树。

|
| 图 7 回归树模型结构示意图 Fig. 7 The structure of Regression Tree model |
(表 2)统计了CART模型每个输入自变量对于构建模型的贡献度, 可以看出贡献度最大的是NIR波段, 其次是NDVI和DVI, 贡献度分别达到64.60和59.36, AET和Precipitation贡献度均为13.51而Aspect的贡献度最低仅为10.97。这个排名在一定程度上体现了每个自变量在构建模型中的权重。其中NIR波段贡献度最高, 原因是灌木属于木本植物, 主要生长方式是通过根和茎因增粗生长从而形成大量的木质结构, 因此, 与叶绿素含量较高的草本植物相比, 灌木对于红光波段的吸收能力有限, 反射的近红外光也越少。由此看来, NIR波段是区分沙地草本植物和灌木植物的最佳因子。
| 自变量 Independent variable |
贡献度 Contribution degree |
|
| 近红外波段NIR | 100.00 | |||||||||||||||||||||||||||||||||||||||||||||||| |
| 归一化植被指数NDVI | 64.60 | ||||||||||||||||||||||||||||||| |
| 差值植被指数DVI | 59.36 | |||||||||||||||||||||||||||| |
| 蒸散量AET | 13.51 | |||||| |
| 降雨量Precipitation | 13.51 | |||||| |
| 坡度Slope | 10.97 | ||||| |
| NIR:近红外波段,Near Infrared;NDVI:归一化植被指数,Normalized Difference Vegetation Index;DVI:差值植被指数,Difference Vegetation Index;AET:实际蒸散量,Actual Evapotranspiration;Precipitation:降水量;Precipitation:降水量 | ||
将选出的自变量代入SVM模型中, 调用Libsvm工具箱使用交叉验证的方法确定支持向量机模型参数gamma和c。如(图 8)所示, 研究中将参数gamma和c的变化范围设置在-10—10之间, 本研究选取树脂复杂度较小的RBF核函数, 它能将样本非线性地映射到一个更高维的空间, 与线性核不同, RBF核函数能够处理属性间的非线性关系。调用网格搜索参数算法并设置K-fold交叉验证(K=5), 最终得出最优惩罚系数c为512, gamma为1。

|
| 图 8 SVM模型参数寻优 Fig. 8 The SVM model parameter optimization |
模型验证结果如(图 9)所示。从图中可知, 两种机器学习模型均可实现一定精度的灌木覆盖度估算, CART与SVM模型的R2分别达到了0.73和0.72, RMSE分别为13.66%和13.73%, 估算精度分别为61.8%和61.6%。尽管两种模型估算精度总体相差不大, 对特定区间灌木覆盖度估算效果却有所差异。当灌木覆盖度低于50%时, SVM模型估算精度较高, 而当覆盖度大于50%时CART模型估算精度较高。

|
| 图 9 两种机器学习模型估算和实测覆盖度对比散点图 Fig. 9 Measured and estimated fraction based on two different machine-learning models |
本研究采用CART及SVM算法对2000—2015年间毛乌素沙地灌木覆盖度进行计算(2012年除外), 部分年份估算结果如(图 10)所示。从总体分布来看, 可以发现两种模型的估算结果一致性较强。对2015年估算结果进行分析表明, 灌木覆盖度高于60%的区域主要分布在毛乌素沙地的南北两缘以及东部地区, 西部地区主要以中低覆盖度为主, 中部及西南地区以流动沙地为主。统计结果显示, CART模型及SVM模型估算毛乌素沙地平均灌木覆盖度分别为28.6%和32.9%, 其中, 覆盖度低于25%的区域分别占总面积的53.6%和36.6%;覆盖度在25%—50%之间的区域分别占总面积的31.4%和34.3%;覆盖度在50%—75%之间的区域分别占总面积的11.5%和25.7%;覆盖度大于75%的区域分别占总面积的3.5%和3.4%。从2000—2015年间时间动态来看, 毛乌素沙地灌木覆盖度呈整体增长趋势, 其中南北两缘及东部地区增长趋势明显, 中部及中西部地区长期处于较低覆盖水平。

|
| 图 10 2000—2015年毛乌素沙地灌木覆盖度分布图 Fig. 10 Map of shrub coverage distribution of Mu Us Sandy from 2000—2015 |
为说明本研究所发展产品特点, 我们以毛乌素沙地为例比较了灌木覆盖度与树木覆盖度产品。美国马里兰大学的Hansen团队发布了首套全球30m分辨率树木覆盖度产品[43], 但该产品计算了高于5m的树木的覆盖度, 该产品目前已成为区域木本植被丰富性的主要数据。然而, 在以灌木覆盖为主的中国北方沙地, 该数据对大范围存在的灌木分布无法反映(图 11), 考虑到该类地区在全球及中国的广泛分布, 开展灌木覆盖度的科学估算及动态分析具有重要的应用意义。本研究提出的灌木覆盖度估算技术体系, 具备全球推广生成相应产品的潜力, 可以对树木覆盖度产品形成有效补充, 可为干旱地区生态系统管理、科学研究提供重要支撑。

|
| 图 11 灌木覆盖产品与树木覆盖产品对比 Fig. 11 Comparison of shrubcover and treecover remote sensing imagery products |
本文提出了一种利用Collect Earth进行地面样本采集、通过Google Earth Engine云平台与机器学习方法估算中高分辨率灌木覆盖度的方法, 并以毛乌素沙地为例开展了应用研究。主要结论如下:
(1) 本研究采用Collect Earth样本收集器进行等距采样的方式构建样本数据集, 解决了样本数据集偏少或样本提取精度较低的问题, 为今后更大尺度的估算提供了新的手段。
(2) 机器学习算法对毛乌素沙地灌木覆盖度估算精度均达到61%以上, 其中, 分类回归树模型确定系数R2为0.73, 均方根误差为13.66%, 支持向量机模型确定系数R2为0.72, 均方根误差为13.73%。两种模型估算精度基本持平, 但对中低和中高覆盖度估算能力各有所长, 分类回归树模型对中高覆盖度区域估算精度高于支持向量机模型, 而在中低覆盖度区域支持向量机模型估算精度高于分类回归树模型。
(3) GEE云平台存储了公开可用的全球尺度近40年的遥感影像以及其他遥感产品, 通过Google数据中心众多超级计算机的快速运算将过去需要花费几天甚至几周时间的数据处理流程在几小时甚至分秒间完成。BP级的数据存储提供了更多的数据选择性, 大大提高了数据质量, 不同的数据源也拉长了数据的时间序列, 使得今后更大尺度上的干旱、半干旱区稀疏植被估算成为了可能。
| [1] |
王兵, 魏江生, 胡文. 中国灌木林-经济林-竹林的生态系统服务功能评估. 生态学报, 2011, 31(7): 1936-1945. |
| [2] |
姚雪玲, 姜丽娜, 李龙, 王锋, 吴波, 郭秀江. 浑善达克沙地6种灌木生物量模拟. 生态学报, 2019, 39(3): 905-912. |
| [3] |
李苗苗.植被覆盖度的遥感估算方法研究[D].北京: 中国科学院研究生院(遥感应用研究所), 2003. http://cdmd.cnki.com.cn/Article/CDMD-80070-2003094573.htm
|
| [4] |
Naidoo L, Mathieu R, Main R, Wessels K, Asner G P. L-band synthetic aperture radar imagery performs better than optical datasets at retrieving woody fractional cover in deciduous, dry savannahs. International Journal of Applied Earth Observation and Geoinformation, 2016, 52: 54-64. DOI:10.1016/j.jag.2016.05.006 |
| [5] |
Liu X, Liu H Y, Qiu S, Wu X C, Tian Y H, Hao Q. An improved estimation of regional fractional woody/herbaceous cover using combined satellite data and high-quality training samples. Remote Sensing, 2017, 9(1): 32. |
| [6] |
Suess S, van der Linden S, Okujeni A, Griffiths P, Leitão P, Schwieder M, Hostert P. Characterizing 32 years of shrub cover dynamics in southern Portugal using annual Landsat composites and machine learning regression modeling. Remote Sensing of Environment, 2018, 219: 353-364. DOI:10.1016/j.rse.2018.10.004 |
| [7] |
Baumann M, Levers C, Macchi L, Bluhm H, Waske B, Gasparri N I, Kuemmerle T. Mapping continuous fields of tree and shrub cover across the Gran Chaco using Landsat 8 and sentinel-1 data. Remote Sensing of Environment, 2018, 216: 201-211. DOI:10.1016/j.rse.2018.06.044 |
| [8] |
Ge J, Meng B P, Liang T G, Feng Q S, Gao J L, Yang S X, Huang X D, Xie H J. Modeling alpine grassland cover based on MODIS data and support vector machine regression in the headwater region of the Huanghe River, China. Remote Sensing of Environment, 2018, 218: 162-173. DOI:10.1016/j.rse.2018.09.019 |
| [9] |
张瑾, 李晓松, 吴炳方. 基于分类回归树的密云水库上游森林覆盖度遥感估算. 遥感技术与应用, 2014, 29(3): 394-400. |
| [10] |
Huang H B, Chen Y L, Clinton N, Wang J, Wang X Y, Liu C X, Gong P, Yang J, Bai Y Q, Zheng Y M, Zhu Y L. Mapping major land cover dynamics in Beijing using all Landsat images in google earth engine. Remote Sensing of Environment, 2017, 202: 166-176. DOI:10.1016/j.rse.2017.02.021 |
| [11] |
高志海, 李增元, 魏怀东, 丁锋, 丁国栋. 干旱地区植被指数(VI)的适宜性研究. 中国沙漠, 2006, 26(2): 243-248. DOI:10.3321/j.issn:1000-694X.2006.02.015 |
| [12] |
Li X S, Zheng G X, Wang J Y, Ji C C, Sun B, Gao Z H. Comparison of methods for estimating fractional cover of photosynthetic and non-photosynthetic vegetation in the Otindag sandy land using GF-1 wide-field view data. Remote Sensing, 2016, 8(10): 800. DOI:10.3390/rs8100800 |
| [13] |
Bastin J, Berrahmouni N, Grainger A, Maniatis D, Mollicone D, Moore R, Patriarca C, Picard N, Sparrow B, Maria Abraham E, Aloui K, Atesoglu A, Attore F, Bassüllü C, Bey A, Garzuglia M, G. García-Montero L, Groot N, Guerin G, Laestadius L, Lowe A J, Mamane B, Marchi G, Patterson P, Rezende M, Ricci S, Salcedo I, Sanchez-Paus Diaz A, Stolle F, Surappaeva V, Castro R. The extent of forest in dryland biomes. Science, 2017, 356(6338): 635-638.
|
| [14] |
Sexton J O, Song X P, Feng M, Noojipady P, Anand A, Huang C Q, Kim D H, Collins K, Channan S, DiMiceli C, Townshend J. Global, 30-m resolution continuous fields of tree cover:Landsat-based rescaling of MODIS vegetation continuous fields with Lidar-based estimates of error. International Journal of Digital Earth, 2013, 6(5): 427-448. DOI:10.1080/17538947.2013.786146 |
| [15] |
Herrmann S M, Wickhorst A J, Marsh S E. Estimation of tree cover in an agricultural parkland of Senegal using rule-based regression tree modeling. Remote Sensing, 2013, 5(10): 4900-4918. DOI:10.3390/rs5104900 |
| [16] |
Brandt M, Hiernaux P, Tagesson T, Verger A, Rasmussen K, Diouf A A, Mbow C, Mougin E, Fensholt R. Woody plant cover estimation in drylands from earth observation based seasonal metrics. Remote Sensing of Environment, 2016, 172: 28-38. DOI:10.1016/j.rse.2015.10.036 |
| [17] |
Higginbottom T P, Symeonakis E, Meyer H, Van der Linden S. Mapping fractional woody cover in semi-arid savannahs using multi-seasonal composites from Landsat data. ISPRS Journal of Photogrammetry and Remote Sensing, 2018, 139: 88-102. DOI:10.1016/j.isprsjprs.2018.02.010 |
| [18] |
李晓松, 李增元, 吴波, 高志海, 白黎娜, 王琫瑜. 基于光谱混合分析的毛乌素沙地油蒿群落覆盖度提取. 遥感学报, 2007, 11(6): 923-930. |
| [19] |
李晓松, 高志海, 李增元, 白黎娜, 王琫瑜. 基于高光谱混合像元分解的干旱地区稀疏植被覆盖度估测. 应用生态学报, 2010, 21(1): 152-158. |
| [20] |
吴俊君, 高志海, 李增元, 王红岩, 庞勇, 孙斌, 李长龙, 李绪志, 张九星. 基于天宫一号高光谱数据的荒漠化地区稀疏植被参量估测(英文). 光谱学与光谱分析, 2014, 34(3): 751-756. DOI:10.3964/j.issn.1000-0593(2014)03-0751-06 |
| [21] |
Gorelick N, Hancher M, Dixon M, Ilyushchenko S, Thau D, Moore D. Google earth engine:planetary-scale geospatial analysis for everyone. Remote Sensing of Environment, 2017, 202: 18-27. DOI:10.1016/j.rse.2017.06.031 |
| [22] |
Langner A, Miettinen J, Kukkonen M, Vancutsem C, Simonetti D, Vieilledent G, Verhegghen A, Gallego J, Stibig H J. Towards operational monitoring of forest canopy disturbance in evergreen rain forests:a test case in continental Southeast Asia. Remote Sensing, 2018, 10(4): 544. DOI:10.3390/rs10040544 |
| [23] |
Dong J W, Xiao X G, Menarguez M A, Zhang G L, Qin Y W, Thau D, Biradar C, Moore Ⅲ B. Mapping paddy rice planting area in Northeastern Asia with Landsat 8 images, phenology-based algorithm and google earth engine. Remote Sensing of Environment, 2016, 185: 142-154. DOI:10.1016/j.rse.2016.02.016 |
| [24] |
Xiong J, Thenkabail P S, Tilton J C, Gumma M K, Teluguntla P, Oliphant A, Congalton R G, Yadav K, Gorelick N. Nominal 30-m cropland extent map of continental Africa by integrating pixel-based and object-based algorithms using sentinel-2 and landsat-8 data on google earth engine. Remote Sensing, 2017, 9(10): 1065. DOI:10.3390/rs9101065 |
| [25] |
Parastatidis D, Mitraka Z, Chrysoulakis N, Abrams M. Online global land surface temperature estimation from Landsat. Remote Sensing, 2017, 9(12): 1208. DOI:10.3390/rs9121208 |
| [26] |
Zhou D J, Zhao X, Hu H F, Shen H H, Fang J Y. Long-term vegetation changes in the four mega-sandy lands in Inner Mongolia, China. Landscape Ecology, 2015, 30(9): 1613-1626. DOI:10.1007/s10980-015-0151-2 |
| [27] |
吴波, 慈龙骏. 毛乌素沙地景观格局变化研究. 生态学报, 2001, 21(2): 191-196. DOI:10.3321/j.issn:1000-0933.2001.02.003 |
| [28] |
冯颖.毛乌素沙地植被盖度变化及其对气候变化的响应[D].北京: 北京林业大学, 2015. http://cdmd.cnki.com.cn/Article/CDMD-10022-1015320319.htm
|
| [29] |
张新时. 毛乌素沙地的生态背景及其草地建设的原则与优化模式. 植物生态学报, 1994, 18(1): 1-16. DOI:10.3321/j.issn:1005-264X.1994.01.008 |
| [30] |
屠志方, 李梦先, 孙涛. 第五次全国荒漠化和沙化监测结果及分析. 林业资源管理, 2016(1): 1-5, 13-13. |
| [31] |
Abatzoglou J T, Dobrowski S Z, Parks S A, Hegewisch K C. TerraClimate, a high-resolution global dataset of monthly climate and climatic water balance from 1958-2015. Scientific Data, 2018, 5: 170191. DOI:10.1038/sdata.2017.191 |
| [32] |
孙斌, 李增元, 郭中, 高志海, 王琫瑜. 高分一号与Landsat TM数据估算稀疏植被信息对比. 遥感信息, 2015, 30(5): 48-56. DOI:10.3969/j.issn.1000-3177.2015.05.008 |
| [33] |
Huete A R. A soil-adjusted vegetation index (SAVI). Remote Sensing of Environment, 1988, 25(3): 295-309. DOI:10.1016/0034-4257(88)90106-X |
| [34] |
Bey A, Sánchez-Paus Díaz A, Maniatis D, Marchi G, Mollicone D, Ricci S, Bastin J F, Moore R, Federici S, Rezende M, Patriarca C, Turia R, Gamoga G, Abe H, Kaidong E, Micel G. Collect earth:land use and land cover assessment through augmented visual interpretation. Remote Sensing, 2016, 8(10): 807. DOI:10.3390/rs8100807 |
| [35] |
Breiman L, Friedman J H, Olshen R A and Stone C J. Classification and Regression Trees. Belmont, Calif.: Wadsworth International Group, 1984: 1-358.
|
| [36] |
赵萍, 傅云飞, 郑刘根, 冯学智, Satyanarayana B. 基于分类回归树分析的遥感影像土地利用/覆被分类研究. 遥感学报, 2005, 9(6): 708-716. |
| [37] |
Cortes C, Vapnik V. Support-vector networks. Machine Learning, 1995, 20(3): 273-297. |
| [38] |
周绍磊, 廖剑, 史贤俊. RBF-SVM的核参数选择方法及其在故障诊断中的应用. 电子测量与仪器学报, 2014, 28(3): 240-246. |
| [39] |
张睿, 马建文. 支持向量机在遥感数据分类中的应用新进展. 地球科学进展, 2009, 24(5): 555-562. DOI:10.3321/j.issn:1001-8166.2009.05.012 |
| [40] |
Chang C C, Lin J C. LIBSVM:a library for support vector machines. ACM Transactions on Intelligent Systems and Technology, 2011, 2(3): 27. |
| [41] |
刘艳慧, 蔡宗磊, 包妮沙, 刘善军. 基于无人机大样方草地植被覆盖度及生物量估算方法研究. 生态环境学报, 2018, 27(11): 2023-2032. |
| [42] |
宋军伟, 张友静, 李鑫川, 杨文治. 基于GF-1与Landsat-8影像的土地覆盖分类比较. 地理科学进展, 2016, 35(2): 255-263. |
| [43] |
Hansen M C, Potapov P V, Moore R, Hancher M, Turubanova S A, Tyukavina A, Thau D, Stehman S V, Goetz S J, Loveland T R, Kommareddy A, Egorov A, Chini L, Justice C O, Townshend J R G. High-resolution global maps of 21st-century forest cover change. Science, 2013, 342(6160): 850-853. DOI:10.1126/science.1244693 |